文献情報
- タイトル:Training Restricted Boltzmann Machines With a D-Wave Quantum Annealer
- 著者:Vivek Dixit, Raja Selvarajan, Muhammad A. Alam, Travis S. Humble and Sabre Kais\
- DOI:https://doi.org/10.3389/fphy.2021.589626
- 出版年:2021
概要
制限ボルツマンマシン(RBM)は、ニューラルネットワークのひとつです。RBMには可視層と隠れ層というものがあり、同じ層同士では結合しないのが特徴的です。通常、RBMを学習する際、ノード(層の要素数)が多いと計算量が増えてしまうため、コンストラクティブ・ダイバージェンス(CD)という手法で近似的に学習します。また、別の手法として、量子アニーリング(QA)の性質を利用し、その出力値から学習する手法があります。本論文では、CDで学習されたRBMとQAで学習されたRBMを使って、画像分類、画像再構成、対数尤度の精度を比較しました。結果として、画像分類では、QAはCDと同等の正解率が得られましたが、画像再構成と対数尤度では、CDの方が良い結果が得られることがわかりました。
背景
RBMとは
RBMは、あるデータ(画像、音声など)が生み出される経験分布を模倣することを目的とします。経験分布$𝑝_0(𝑣)$は式(1)で表されます。
$$
\begin{align*}
p_0(X) = \frac{1}{N} \sum_{i=1}^N \delta(X – X_i) \tag{1}
\end{align*}
$$
デルタ関数で表現され、$N$個のデータのうち、該当するデータ値$X$が入力されるとその確率を出力します。
次に、RBMの具体的な構造を図1に示します。RBMはノードに0か1の値を持つ、可視層$\vec{v}$と隠れ層$\vec{h}$で構成され、それぞれにバイアス$\vec{b}$、$\vec{c}$が加味されます。2層間は重み$W$で結合していますが、同じ層同士では結合しません。
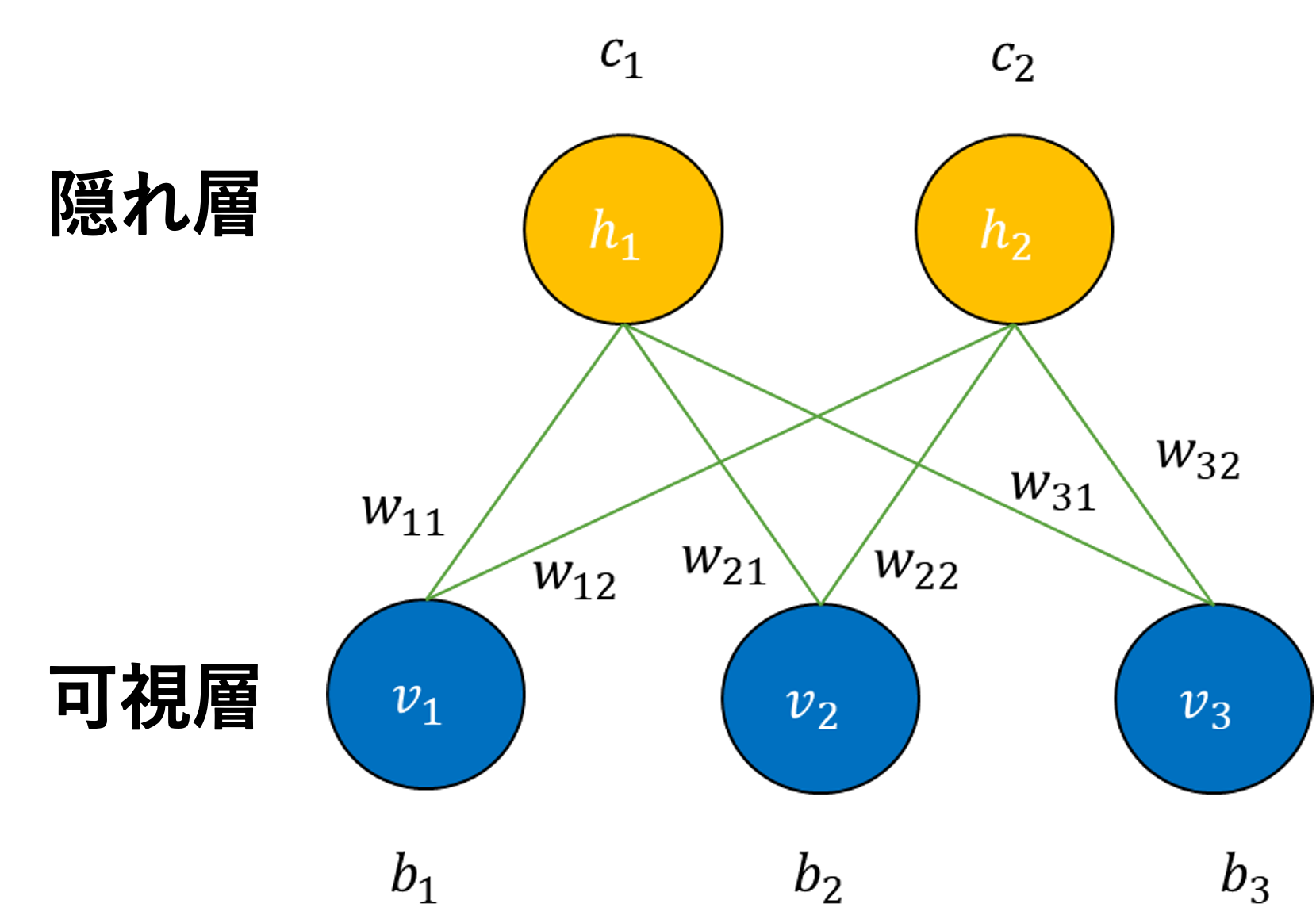
RBMを式で表すと式(2)のようになります。
$$
\begin{align*}
q_\theta(v, h) = \frac{1}{Z(\theta)}e^{-E_\theta(v, h)} \tag{2}
\end{align*}
$$
$$
\begin{align*}
E_\theta(v, h) &= – \sum_{i=1}^{n} \sum_{j=1}^{m} w_{ij}v_ih_j – \sum_{i=1}^{n} b_iv_i – \sum_{j=1}^{m} c_jh_j \\ &= – v^\mathrm{T}Wh – b^\mathrm{T}v – c^\mathrm{T}h \tag{3}
\end{align*}
$$
$$
\begin{align*}
Z(\theta) = \sum_{v, h} e^{- E_{\theta}(v, h)} \tag{4}
\end{align*}
$$
- $w_{ij}$ : $i$番目の可視層と$j$番目の隠れ層を結合する重み
- $v_i$ : $i$番目の可視層の値(0 or 1)
- $h_j$ : $j$番目の隠れ層の値(0 or 1)
- $b_i$ : $i$番目の可視層のバイアス
- $c_j$ : $j$番目の隠れ層のバイアス
$q_\theta(v, h)$ はRBMで模倣する確率分布であり、$E_\theta(v, h)$ はエネルギー、$Z(\theta)$ は分配関数(規格化定数)と呼ばれます。また、変数$\theta$は、重み$W \equiv (w_{11}, w_{12}, \cdots, w_{ij}, \cdots, w_{nm})$、可視層のバイアス$\vec{b} \equiv (b_1, \cdots, b_i, \cdots, b_n)$、隠れ層のバイアス$\vec{c} \equiv (c_1, \cdots, c_j, \cdots, c_m)$を表します。
分配関数は、可視層と隠れ層の値のすべての組み合わせを計算した総和であるため、ノードが増えると指数関数的に計算量が増えていきます。理由については後述しますが、RBMを学習する際、この分配関数の計算が困難であるため、近似的な計算手法が提案されてきました。
制限ボルツマンマシンの学習
RBMの学習方法の詳細については、別記事「ボルツマンマシンと制限ボルツマンマシン」をご覧ください。本記事では、RBMの学習方法について簡潔に説明します。RBMの学習の指標には、Kellback-Leibler情報量(KL情報量)を使います。KL情報量は、RBMの確率分布$𝑞_𝜃(𝑣)$と経験分布$𝑝_0(𝑣)$がどのくらい近いか評価します。二つの確率分布が近づくほど、KL情報量は小さくなります。
$$
\begin{align*}
KL(p_0(v) || q_\theta(v)) &= \sum_v p_0(v) \log \frac{p_0(v)}{q_\theta(v)} \\ &= \sum_v [p_0(v) \log p_0(v) – p_0(v) \log q_\theta(v)] \\
&= \mathbb{E}_{p_0(v)}[\log p_0(v)] – \mathbb{E}_{p_0(v)}[\log q_\theta(v)] \tag{5}
\end{align*}
$$
ここで変数$\theta$を含む項は$\mathbb{E}_{p_0(v)}[\log q_\theta(v)]$のみであり、この項を最大化することによりKL情報量を最小化することが可能になります。そこで、KL情報量の変数$\theta$を含む項を
$$
L = \mathbb{E}_{p_0(v)}[\log q_\theta(v)] \tag{6}
$$
と置き、$L$を最大にしてRBMの確率分布$q_\theta(v)$が経験分布$p_0(v)$に近づくように勾配降下法で学習していきます。勾配降下法は、以下の式で表されます。
$$
\begin{align*}
\theta \leftarrow \theta – \eta \frac{\partial L}{\partial \theta} \tag{7}
\end{align*}
$$
$\eta$は学習率で、$L$の勾配を計算し変数$\theta$を更新していくことで、$L$を最大にする$\theta$をもとめることが可能になります。経験分布の式(1)を用いて、$\frac{\partial L}{\partial \theta}$は以下の式で表されます。
$$
\begin{align*}
-\frac{\partial L}{\partial \theta} &= \mathbb{E}_{p_0(v)}[\mathbb{E}_{q_\theta(h|v)}[\frac{\partial E_\theta(v, h)}{\partial \theta}]] – \mathbb{E}_{q_\theta(v, h)}[\frac{\partial E_\theta(v, h)}{\partial \theta}] \\
&= \frac{1}{N} \sum_{k=1}^{N}\mathbb{E}_{q_\theta(h|v^{(k)})}[\frac{\partial E_\theta(v^{(k)}, h)}{\partial \theta}] – \mathbb{E}_{q_\theta(v, h)}[\frac{\partial E_\theta(v, h)}{\partial \theta}] \tag{8}
\end{align*}
$$
この式の一項目は、経験分布のデータに関する平均で、ポジティブフェーズと呼ばれます。一方、二項目はRBMの確率分布に関する平均でネガティブフェーズと呼ばれます。変数$\theta$を各種のパラメータ(重み$W$、バイアス$\vec{b}$、$\vec{c}$)に関して表すと以下の式になります。
$$
\begin{align*}
-\frac{\partial L}{\partial w_{ij}} = \frac{1}{N} \sum_{k=1}^{N}v_i^{(k)}\sigma(\lambda_j^{(k)}) – \mathbb{E}_{q_\theta(v, h)}[v_ih_j] \tag{9}
\end{align*}
$$
$$
\begin{align*}
-\frac{\partial L}{\partial b_i} = \frac{1}{N} \sum_{k=1}^{N}v_i^{(k)} – \mathbb{E}_{q_\theta(v, h)}[h_j] \tag{10}
\end{align*}
$$
$$
\begin{align*}
-\frac{\partial L}{\partial c_j} = \frac{1}{N} \sum_{k=1}^{N}\sigma(\lambda_j^{(k)}) – \mathbb{E}_{q_\theta(v, h)}[h_j] \tag{11}
\end{align*}
$$
ただし、$\sigma(x) = \frac{e^x}{1 + e^x}$、$\lambda_j^{(k)} = \sum_{k=1}^N (w_{ij}v_i^{(k)} + c_j)$とします。
学習の問題点として、ネガティブフェーズの期待値では、可視層$v$と隠れ層$h$のすべての組み合わせに関する和を計算するので、可視層の数を$n$、隠れ層の数を$m$とすると、$2^{n+m}$通りになり、ノード数が増える毎に計算時間が指数関数的に増えていきます。そこで、解決方法として、マルコフ連鎖モンテカルロ法(MCMC)の一つであるCDと、QAから得るサンプリング手法を紹介します。
手法① CDによるサンプリング
図2のように、可視層$v^\mu$に経験分布から得られる$\mu$番目のデータを入力し、条件確率に基づき$k$回サンプリングします(CD-k)。それぞれの確率分布は、以下の通りです。
$$
\begin{align*}
q_\theta(h|v) &= \frac{q_\theta(v, h)}{q_\theta(v)}\\
&= \prod_j \frac{e^{(\sum_i w_{ij}v_i + c_j)h_j}}{1 + e^{\sum_i w_{ij}v_i + c_j}}\\
&= \prod_j \frac{e^{\lambda_j h_j}}{1 + e^{\lambda_j}} \tag{12}
\end{align*}
$$
ただし、$\lambda_j = \sum_i w_{ij}v_i + c_j$とする。
$$
\begin{align*}
q_\theta(v|h) &= \frac{q_\theta(v, h)}{q_\theta(h)}\\
&= \prod_i \frac{e^{(\sum_j w_{ij}h_j + b_j)v_i}}{1 + e^{\sum_j w_{ij}h_j + b_j}}\\
&= \prod_i \frac{e^{\lambda_i v_i}}{1 + e^{\lambda_i}} \tag{13}
\end{align*}
$$
ただし、$\lambda_i = \sum_j w_{ij}h_j + b_j$とする。
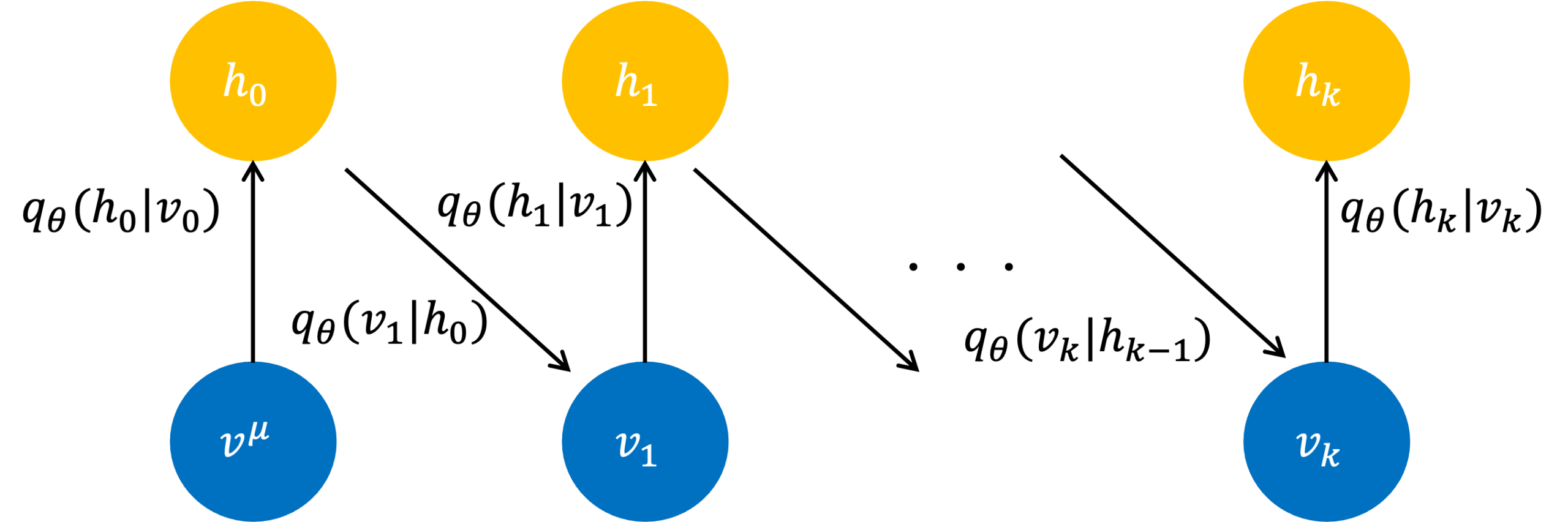
具体的には可視層のノードを$n$、隠れ層のノードを$m$とすると、まずサイズ$n$のデータを可視層に入力し、$j$番目の隠れ層の値を1に固定して、条件付き確率をもとめます。1に固定することでノードが1になる確率で統一してサンプリングすることが可能になります。
$$
q_\theta(h_j = 1 | v) = \sigma(\lambda_j) \tag{14}
$$
隠れ層$h$をすべてサンプリングしたら、今度は$i$番目の可視層の値を1に固定して、隠れ層を基に条件付き確率で可視層$v$のサンプリングをします。
$$
q_\theta(v_i = 1 | h) = \sigma(\lambda_i) \tag{15}
$$
この操作をある程度の回数繰り返し、その時の$v$、$h$の値を使ってネガティブフェーズの項$\mathbb{E}_{q_\theta(v, h)}[\frac{\partial E_\theta(v, h)}{\partial \theta}]$を近似的にもとめます。経験的に、可視層と隠れ層を1回ずつサンプリングするCD-1がRBMの学習に良く用いられ、本論文の実験でもCD-1が学習に使われていました。
手法② QAを用いたサンプリング
RBMの変数$\theta$をD-WaveマシンのQAに入力すると、ギブス・ボルツマン分布に近い出力が得られると知られています。ギブス・ボルツマン分布は先述の式(2)に対応します。
$$
\begin{align*}
q_\theta(v, h) = \frac{1}{Z(\theta)}e^{-E_\theta(v, h)} \tag{2}
\end{align*}
$$
式(2)を見るとエネルギー$E_\theta(v, h)$が小さいと、確率分布$q_\theta(v, h)$は大きくなります。QAは最適解だけでなく、エネルギーの小さい解も多くサンプリングするので、QAの確率分布は$q_\theta(v, h)$と近くなると言われています。
QAでは、式(16)のQUBO問題における目的関数$E(\vec{x})$を最小化にする最適解$\vec{x}$に近い値をもとめます。
$$
\begin{align*}
E(\vec{x}) = \sum_i Q_{ii}x_i + \sum_{i < j} Q_{ij} x_i x_j \tag{16}
\end{align*}
$$
定数$Q$はRBMの変数$\theta$に対応し、入力値$\vec{x}$はRBMの可視層と隠れ層の値に対応します。
$Q_{ij}$ : n×mの行列の内、上三角形の要素で重み$W$に対応
今回利用された量子アニーラーのD-Wave 2000Qは、量子ビットの埋め込みの問題や、量子ビットのコヒーレンス時間が短くなる問題の影響でノイズが入り、得られる出力にばらつきがあります。これにより、最適解に近い値をサンプリングすることができます。
具体的にQAを用いたサンプリングによるRBMの学習の流れは、以下の通りです。
②QAからサンプルを得る。
③QAの出力$E(x)$から可視層$v$、隠れ層$h$の値を得て、ネガティブフェーズの項を近似的にもとめる。
④勾配法より、$Q$を更新する。
⑤$Q$の値がある程度収束されるまで②~④を繰り返す。
この過程により、RBMの学習が可能になります。
実験手法
RBMの訓練とテストには、BAS(bars and stripes)データセットを用いました。このデータセットは、画像の大きさ8×8(64ピクセル)の縦縞(bars)と横縞(stripes)から成り、1ピクセルあたり青色がビットの0に対応し、黄色が1に対応します。また、図3の右下の2ビット(赤枠)は、分類問題におけるラベルを示し、青黄(01)は縦縞、黄青(10)は横縞と判定し、青青(00)と黄黄(11)はエラーとします。
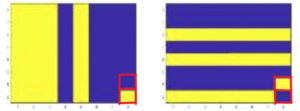
本論文の実験では、BASデータセットの512枚のデータのうち、400枚をRBMの訓練データに、112枚をテストデータに用います。
実験① 画像分類
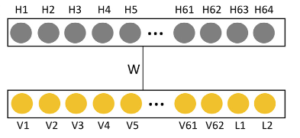
まず、400枚の訓練データでCD-1で学習されたRBMとQAで学習されたRBMを用意します。この時、RBMは、可視層と隠れ層のノードを64に設定します。次に、テストデータをRBMの可視層に入力する際、図4のように、データの64ビットのうち62ビットを入力し、分類問題におけるラベルL1とL2にはランダムに0か1を入力します。その後、ギブスサンプリングを50回行い、L1とL2の値を求めます。この作業をテストデータ112枚分行い、以下の式で表される正解率によってRBMの分類精度を評価します。
$$正解率 = \frac{正しく予測した数}{テストデータの数(112枚)}$$
最終的に、CD-1学習の正解率とQA学習の正解率を比較します。
実験② 画像再構成
まず、テストデータの64ビットのうち、いくつかを0か1のランダムな値にしてビットを崩壊させて、学習済みのRBMの可視層に入力します。崩壊させるビットの数は以下の3通りです。
- 分類ラベル(2ビット)
- 画像右下の4×4(16ビット)
- 全てのビット(64ビット)
入力後、ギブスサンプリングを50回行い、可視層の値を求めます。ギブスサンプリングとは、式(14)と式(15)を計算して交互にサンプリングすることです。定常確率になるまでサンプリングをする点でCDと異なります。テストデータ112枚分の結果から、次の式で表される再構築誤差によって、RBMの画像に対する再構成の精度を評価します。
$$再構築誤差 = \sum_{i=1}^n \sum _{t=1}^N (v_{(i)}^{(t)} – v_{i}’)^2$$
$n$:可視層の数, $N$:データの数
ただし、$v_{i}^{(t)}$は、画像を崩壊させる前のデータ$t$について、$i$番目の可視層の値を示し、$v_{(i)}’$は、崩壊させたデータを再構成した時の$i$番目の可視層の値を示します。
最終的に、CD学習の誤差とQA学習の再構築誤差を比較します。
実験③ 対数尤度
RBMの学習では、できる限り対数尤度$L$の期待値を最大にすることが求められます。
$$L = \mathbb{E}_{p_0(v)}[\log q_{\theta}(v)]$$
そこで、CD学習とQA学習のどちらの対数尤度が大きいか比較します。
まず、隠れ層を64個のノードから20個のノードに変更します。次に、エポック毎の対数尤度$L$をそれぞれ計算し、最終的に対数尤度比較を行います。
結果
実験結果① 画像分類
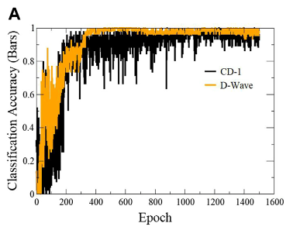
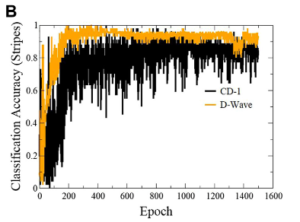
以下に画像分類の正解率比較の結果を示します。図5は、エポック毎の縦縞の正解率を示し、図6は、エポック毎の横縞の正解率を示します。黒線が、CD-1で学習されたRBMで、オレンジ線がD-Wave 2000Qで学習されれたRBMです。どちらも学習回数300あたりで正解率は0.9を超えていますが、CD-1の方は、正解率の変動が大きいことが確認できます。このことから、画像分類ではQA学習の方が安定した正解率で画像分類ができることがわかります。
実験結果② 画像再構成
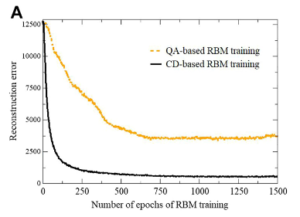
次に、画像再構成の実験結果を示します。図7は、横軸がエポック数、縦軸が再構築誤差を表し、オレンジ色の点線がQA学習のRBMで、黒線がCD学習のRBMを示します。QAよりCDの方が少ない学習回数で再構築誤差が小さくなっていることがわかります。したがって、CDのRBMの方が、正解の画像により近く再構成できているので、学習器の精度が良いのは、CD学習であると言えます。
次に、図8は、3つの条件で画像を崩壊させて、CD学習とQA学習で画像再構成させた一例を示します。まず、Aで分類ラベルを崩壊させたものを入力すると、CD、QAともに正しく画像を再構成していることがわかります。次に、Bで16ビットを崩壊させたものを入力すると、CDでは正しく再構成できてますが、QAでは、2ビット間違えていることがわかります。さらに、Cですべてのビットを崩壊させたものを入力すると、CDではbarと判定して正しく再構成していますが、QAではstripeと判定するも、横縞として正しく再構成できていないことがわかります。
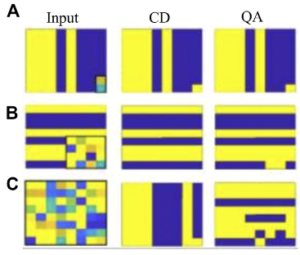
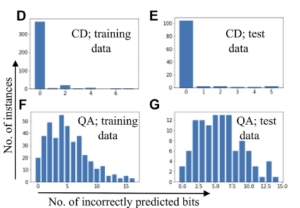
図8は、16ビット崩壊させる条件で再構成させた時の正解数を表します。横軸が1つのデータにおいて再構成できなかったビットの数を示し、縦軸はデータの総数を示します。D、EはCDについての結果で、訓練データ400枚、テストデータ112枚でほとんどが再構成できており、間違ったビットの数は最大でも7ビットでした。一方で、F、GはQAについての結果で、Fの訓練データ時から間違える数が多いことからややアンダーフィッティングしていることがわかり、Dのテストデータの時では、16ビット中、14ビット間違えることもありました。
実験結果③ 対数尤度
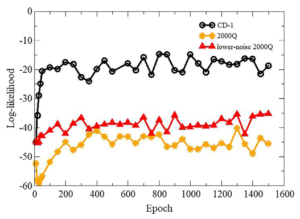
図10は、エポック毎の対数尤度の値を示します。黒のプロットは、CD-1で学習されたRBMの場合で、橙のプロットは、QAで学習されたRBMの場合です。CD-1学習のRBMの方が、QA学習のRBMより、対数尤度が大きいことから、CD-1学習の方が、真のモデルの確率分布により近づけられていることが言えます。QA学習の値が低い原因は、QAの埋め込みの問題によって、計測にノイズが含まれてしまったことが考えられます。そこで、追加実験として低ノイズに調節されたQA学習を用いると、わずかに値が良くなりました。
結論
本論文では、期待値計算の計算困難性というRBMの課題をCDとQAの2つの手法で対処し比較しています。具体的には、CD-1のサンプリングで学習されたRBMと、D-Waveマシンによるサンプリングで学習されたRBMを画像分類、画像再構成、対数尤度で精度を比較しました。画像分類では、QA学習のRBMの方が、安定した正解率を出しました。一方で、画像再構成と対数尤度では、CD学習のRBMの方が良い結果を出しました。
あとがき
本論文の解説記事を書くにあたって、RBMとQAについて理解を深めることができました。実験1のQAの方が分類の精度が高いことについて、私はQAのサンプリングの方が幅広く、学習のオーバーフィッティングを防いだからだと思いました。今回利用されたQAは、D-Wave 2000Qであり、現在は利用できなくなっているため、新たなD-Wave Advantageを用いた場合の精度比較がどのような結果になるか興味を持ちました。
本記事の作成者
嶋﨑司晃 (メンタリング: 鹿内怜央)