今回はT-QARD勉強会(2026年3月1日-3月8日)で学んだことを記事にしました。
概要
量子アニーリング(QA)は最適化問題を解くだけでなく、ボルツマン機械学習にも使われています。これは、QAから得られる出力値の分布がボルツマン分布に近いことを前提にしています。今回は、QAの代わりにシミュレーテッド量子アニーリング(SQA)を用いて、どの温度のボルツマン分布に近いのか確かめました。その際、エネルギー分布だけでなく、磁化やオーバーラップといった指標を使って別視点の評価を行いました。さらにそれぞれのサンプリングを使ってRBMを学習し、実際にどのようなサンプリングの分布になっているか確かめました。結果として、SQAの分布はボルツマン分布に従う様子が見らましたが、T=1.0のボルツマン分布に補正するとずれがみられました。また、SQA学習のRBMのサンプリング分布はMCMCベースのRBMよりも低エネルギー帯に分布していることがわかりました。
原理
このセクションでは、ボルツマン分布を近似的にもとめるメトロポリス法という手法を説明します。
メトロポリス法
式(1)のようなイジング問題を解く時、
$$ H(\vec{\sigma}) = – \sum_{i<j} J_{i,j} \sigma_i \sigma_j – \sum_i h_i \sigma_i \tag{1} $$
ボルツマン分布は以下の式(2), (3)に従います。
$$ P(\vec{\sigma}|\beta) = \frac{1}{Z} e^{-\beta H(\vec{\sigma})} \tag{2} $$
$$ Z = \sum_{\vec{\sigma}}e^{-\beta H(\vec{\sigma})} \tag{3} $$
$\beta$は逆温度で、Zは分配関数と呼ばれます。Zは取りうるすべてのエネルギー状態の和であるため、問題サイズが増えると計算量が指数的に増えてしまい、計算リソースの上限を超えてしまいます。そこで、マルコフ連鎖モンテカルロ法(MCMC法)の考え方を使って、近似的にボルツマン分布をもとめます。MCMC法とは、次の状態が現在の状態のみで決定される時、乱数を使って全体の分布をシミュレーションする方法です。今回は、MCMC法の一つであるメトロポリス法を使って、ボルツマン分布をもとめます。次の1.~5.がその具体的な方法です。
1. N個のスピン$\vec{\sigma}$の内、どれか一つをランダムに選び、スピンを反転(-1→1, 1→-1)させる。
2. エネルギー値を計算して、どのくらい変化したか$\Delta E$を求める。
3. $\Delta E$ ≦ 0なら値を受理し、$\Delta E$ > 0なら確率$𝑃=e^{-\beta \Delta E}$で受理する。
4. 受理されるときは、スピンを反転させて、そうでないならそのままにする。
5. 1.~4.を繰り返す。
次のセクションでは、今回の実験で量子アニーリング(QA)の代わりに用いたシミュレーテッド量子アニーリング(SQA)について説明します。
シミュレーテッド量子アニーリング(SQA)
量子アニーリング(QA)では、横磁場をかけることによって生まれる量子トンネル効果で基底状態(最適解)を探索します。SQAでは、スピンのレプリカをいくつか用意して、量子トンネル効果を古典的な熱揺らぎに置き換えてQAのシミュレーションをします。具体的には、式(4)のようにHの値が最小になるように動作します。$m$はトロッターと呼ばれる、スピンのレプリカの数で、$\Gamma$が横磁場の強度を表します。
$$H = -\frac{\beta}{m} \sum_l^m (\sum_i h_{i,l} \cdot x_{i,l} – \sum_{i,j} J_{ij, l} \cdot x_{i, l} \cdot x_{j, l}) -\frac{1}{2} \log \tanh (\frac{\beta \Gamma}{m}) \sum_l^m \sum_i x_{i,l} \cdot x_{i, l+1} \tag{4}$$
式(4)の第1項目は$m$個のレプリカのすべてエネルギーを計算して平均を取った値を表し、第2項は横磁場$\Gamma$の強度に応じて、隣接するレプリカ同士の影響力が変わります。もし横磁場$\Gamma$が強かったら、$\tanh$関数の値は1に近づき、$\log$関数の値は0に近づきます。その結果、レプリカ同士の値が反転していても、第2項のエネルギーの変化量はあまり変化しなく、さまざまなスピンの状態を取ることができます。その後、だんだん横磁場$\Gamma$を弱めていくと、係数の値が大きくなり、$H$を最小にしようと、隣接するレプリカ同士のスピンの値を同じにしようと作用します。結果として、スピンの状態が1つに決まり、基底状態(最適解)を見つけることが可能になります。
続いてのセクションでは、メトロポリス法でもとめたボルツマン分布とSQAのサンプリングから得られた分布がどのくらい近いのか評価するために、KLダイバージェンスという指標を紹介します。
KLダイバージェンス
今回の実験では、メトロポリス法で作ったボルツマン分布とSQAからサンプリングした分布の2つの確率分布がどのくらい近いか評価します。この2つの確率分布の近さを評価する指標として、KLダイバージェンスを使います(式(5))。
$$D_{KL}(P||Q) = \sum_i p(x_i) \log \frac{p(x_i)}{q(x_i)} \tag{5}$$
$p(x_i)$と$q(x_i)$は、確率分布PとQにそれぞれ従う任意の値の生起確率です。分布が近いほど、0に近づきます。
最後に、ボルツマン分布を図に表示するとき、通常は横軸をエネルギー値としますが、次のセクションでは、別の方法である磁化とオーバーラップを説明します。
磁化
磁化をもとめることで、スピン全体でどちらの向きに揃っているかをみることができます。磁化$m$はあるスピン状態の総和を状態の大きさ(N)で割った値です(式(6))。
$$m = \frac{1}{N} \sum_{i=1}^N \sigma_i \tag{6}$$
$m$が0より大きければ+1に磁化を帯びていて、0より小さければ、-1に磁化を帯びています。
オーバーラップ
一方で、オーバーラップは磁性体のスピンが複雑なまま固まったスピングラスと呼ばれる物質を評価する時によく用いられる指標です。オーバーラップをもとめることで、スピンの向きが特定の向きに固まっているかどうかを調べることができます。オーバーラップ$q$は、2つのスピン状態$\vec{\sigma}と\vec{\tau}$の内積を取り、状態の大きさNで割った値です。(式(7))
$$q = \frac{\vec{\sigma}^T \cdot \vec{\tau}}{N} \tag{7}$$
$q$の値によって次のようなことが言えます。
- $q$ = 1:各組のスピンが一致する
- $q$ = -1:各組のスピンがすべて反転している
- $q$ = 0:各組のスピンは無関係
実験方法
サイズN=32のイジング問題を解くことを考えます。ただし、問題を簡単にするため、式(1)について外部磁場$h$を0にします。係数$J$の値は、$N(0, 1)$に従う乱数で設定します。
実験1
本来、QAでサンプリングするとき、逆温度$\beta$の値は不明です。そこで、どの逆温度の時、ボルツマン分布はSQAのサンプリング分布に一致するのか確かめます。
まず、イジング問題をメトロポリス法で解いた場合と、SQAでサンプリングした場合のエネルギー分布を作成します。ボルツマン分布の逆温度を調節して、SQAの分布とのKLダイバージェンスが最小になる位置をもとめます。
表1 パラメータ設定
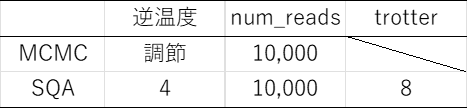
次に、2つの分布が重なる逆温度を固定し、磁化$m$を10,000サンプル分もとめてその分布をグラフに描写します。さらに、10,000サンプルを前半5,000と後半5,000の2グループに分けて、各グループの先頭から1組ずつオーバーラップ$q$をもとめて$q$の分布をグラフに描写します。
実験2
本来、QAのサンプリング分布$P_{qa}(\vec{\sigma})$に重なるように逆温度が調節されたボルツマン分布では、$J$を$\frac{J}{\beta_{mc}}$と置き、改めてQAでサンプリングすると、分布は$\beta=1.0$のボルツマン分布$P_{mc}(\vec{\sigma} | \beta = 1.0)$になると考えられます。
$$ \begin{align*}P_{qa}(\vec{\sigma}) &= \frac{1}{Z} \exp (- \beta_{qa} \sum_{i<j} \frac{J_{ij}}{\beta_{mc}} \sigma_i \sigma_j)\\ &\simeq \frac{1}{Z} \exp (- \sum_{i<j} J_{ij} \sigma_i \sigma_j)\\ &= P_{mc}(\vec{\sigma} | \beta = 1.0) \tag{8} \end{align*}$$
そこで、$J$を逆温度$\beta_{mc}$で割った$\frac{J}{\beta_{mc}}$をSQAでサンプリングし、分布が$\beta = 1.0$のボルツマン分布と一致するか実験します。
実験3
実際に制限付きボルツマンマシン(RBM)の学習に、SQAのサンプリングとメトロポリス法によるサンプリングを用いて、2つの学習器の性能とサンプリング分布の様子をみます。データセットには、手書き数字データセット(MNIST)を用いて、詳細なパラメータと問題設定は表2のようにしました。
表2 RBMのパラメータ設定

まず、2つの訓練データで学習された学習器にテストデータを入力し、出力で画像を再構成しているか2乗平均誤差(MSE)で評価します。次に、学習後のパラメータ(重み$W$、バイアス$b$、$c$)を使って改めてサンプリングを行い、どのような分布の関係になるか比較します。
結果
結果1
まず、KLダイバージェンスが最小となるようなボルツマン分布とSQAのサンプリング分布は図1のようになりました。
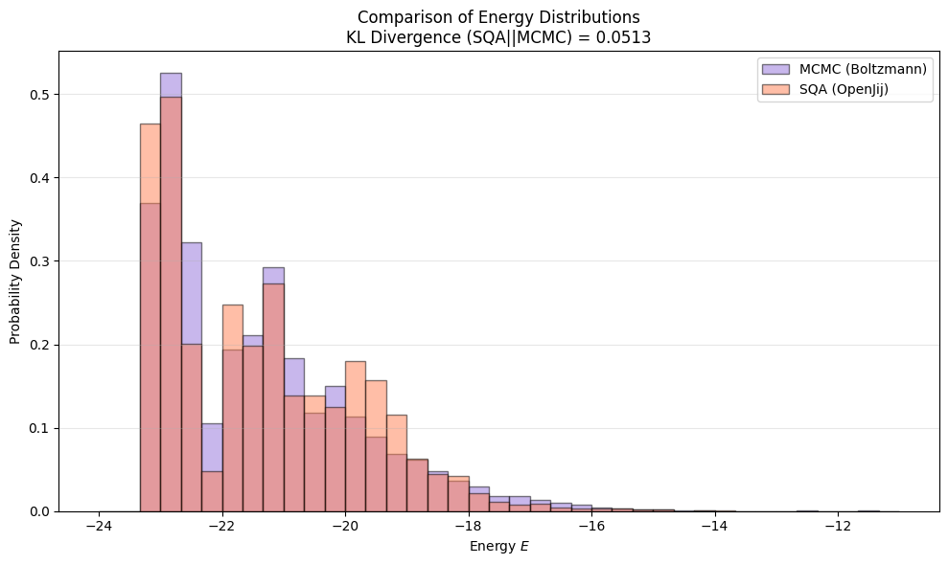
図1 ボルツマン分布とSQAのサンプリング分布
KLダイバージェンスの値は0.05で分布が似ている様子がわかります。この時のボルツマン分布の逆温度は$\beta_{mc} = 2.0$でした。
次に、ボルツマン分布の逆温度を$\beta_{mc} = 2.0$に固定して、それぞれの磁化の分布を描写すると図2のようになりました。KLダイバージェンスの値は0.01で分布が似ており、+側と-側に均等に分布している様子がわかります。
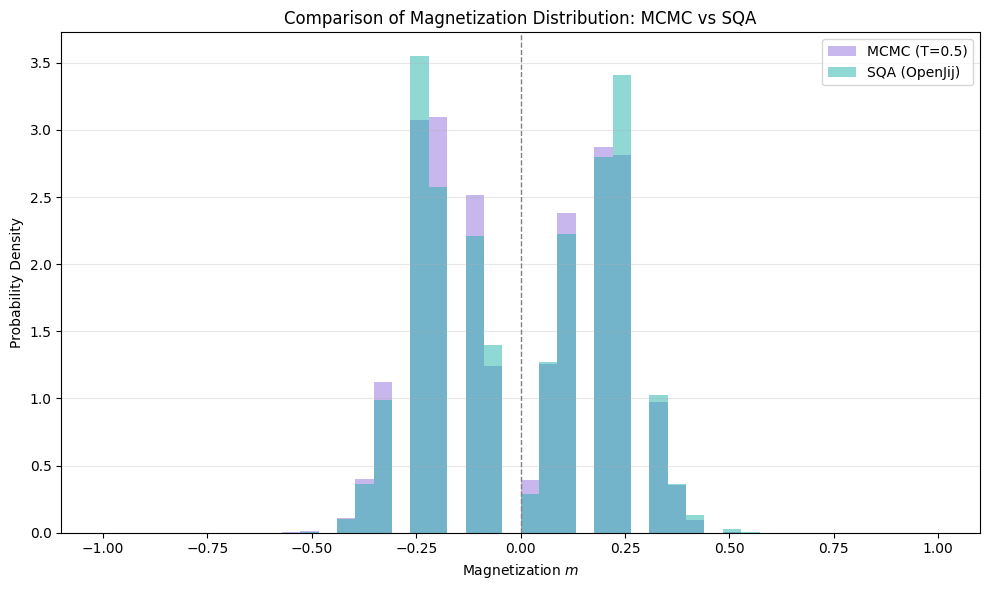
図2 磁化の分布
続いて、サンプリング数10,000の内、前半5,000と後半5,000に分けて、ペアを作り、オーバーラップ$q$を求めてグラフに描写すると図3のようになりました。ボルツマン分布は、$q = -0.8, -0.8$あたりで山ができていますが、SQAの分布は$q = -0.7~0.7$で一様です。KLダイバージェンスの値からも分布が似ていないことがわかります。
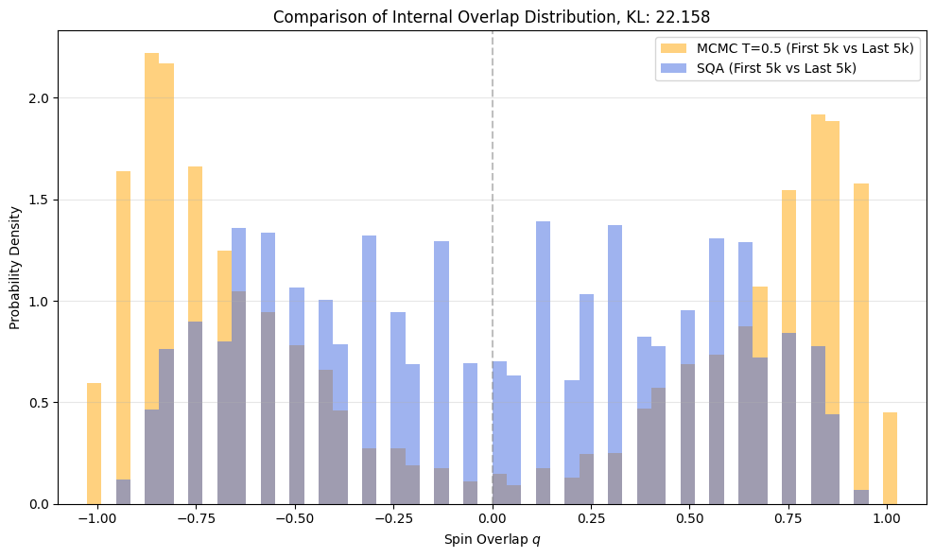
図3 オーバーラップの分布
結果2
$J$を$\frac{J}{\beta_{mc}}$と置き、SQAでサンプリングした時の分布は図4のようになりました。SQAの分布は$\beta = 1.0$のボルツマン分布と比べて、山なりが鋭くなり、エネルギー分布は右側に寄っていることがわかります。
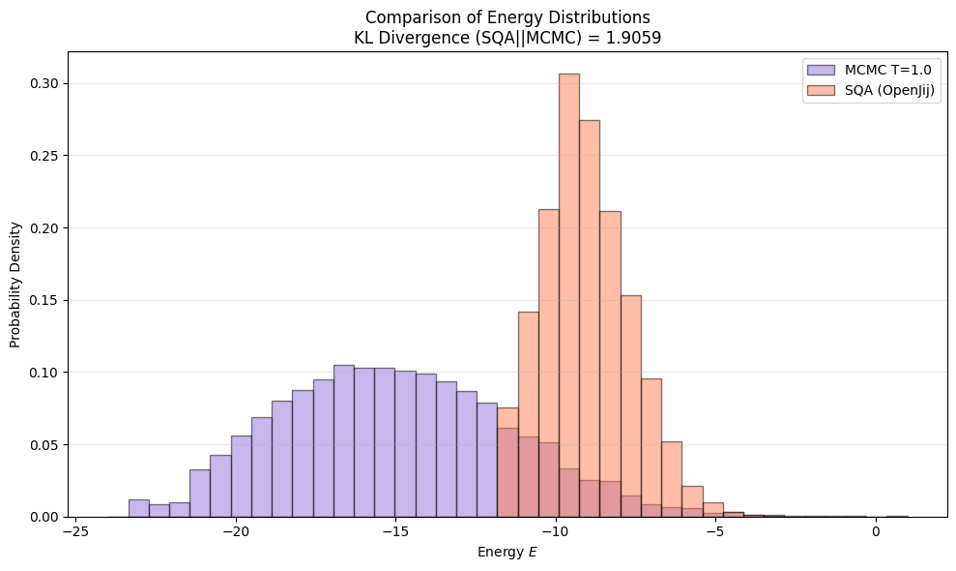
図4 実験2におけるボルツマン分布とSQA分布
また、KLダイバージェンスが最小になる箇所でボルツマン分布の逆温度を調節すると$\beta = 1.6$となりました。
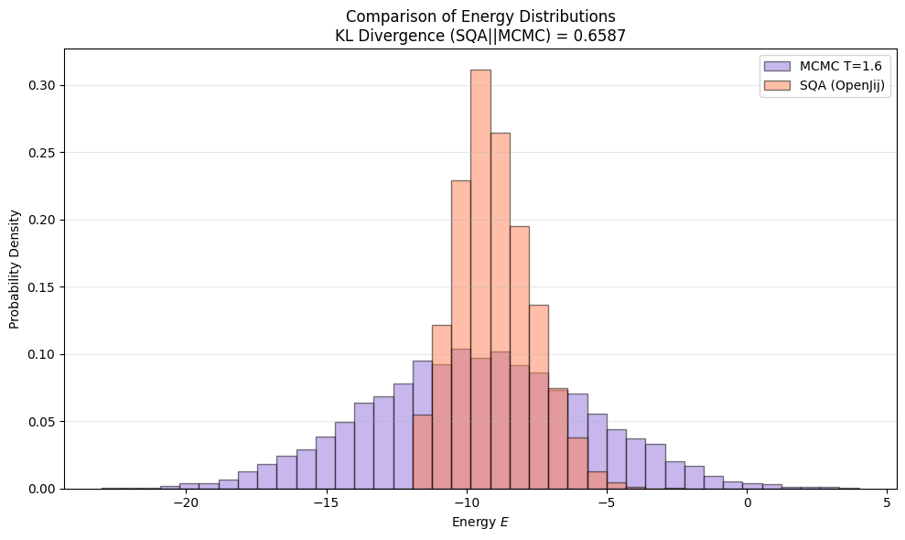
図5 補正したSQA分布
結果3
図6はメトロポリス法のサンプリングで学習したRBM(MCMC-RBM)とSQAのサンプリングで学習したRBM(SQA-RBM)のエポック毎の損失誤差の変化を表します。訓練データによる学習ではSQAの方が損失が小さいことがわかります。また、実行時間に関しては、MCMC-RBMで8秒、SQA-RBMで1時間44分35秒かかり、SQAによる学習は時間がかかることがわかりました。
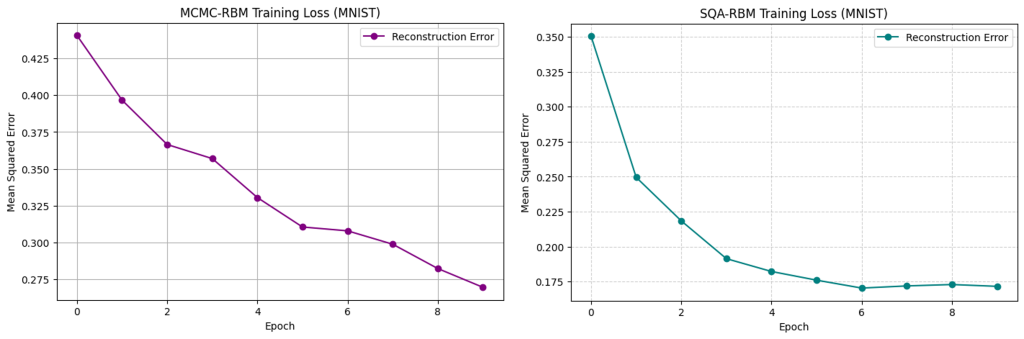
図6 エポック毎の損失誤差
次に学習器にテストデータを入力し、出力で画像再構成してMSEで評価した結果が図7になります。MCMC-RBMはうまく画像再構成ができている様子がみれますが、SQA-RBMは画像がどれも似たようなものになってしまっています。テストデータによるMSEは、MCMC-RBMの方が良いです。
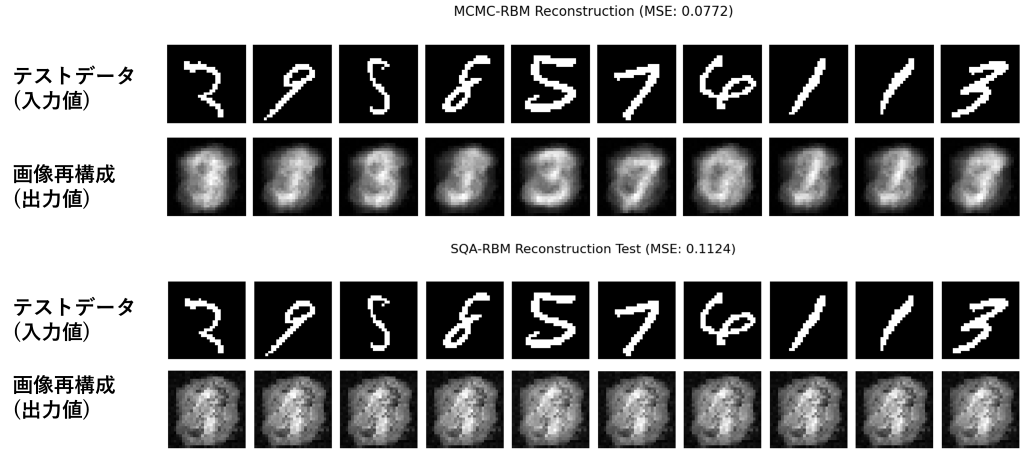
図7 テストデータの画像再構成
さらに、学習した後の学習器のパラメータ(重み$W$、バイアス$b$、$c$)を使って、改めてサンプリングした結果が図8になります。SQAの分布は低エネルギー帯で山が左側に偏って分布しており、MCMC-RBMの方の分布は高エネルギー帯で山が対称な分布をしています。
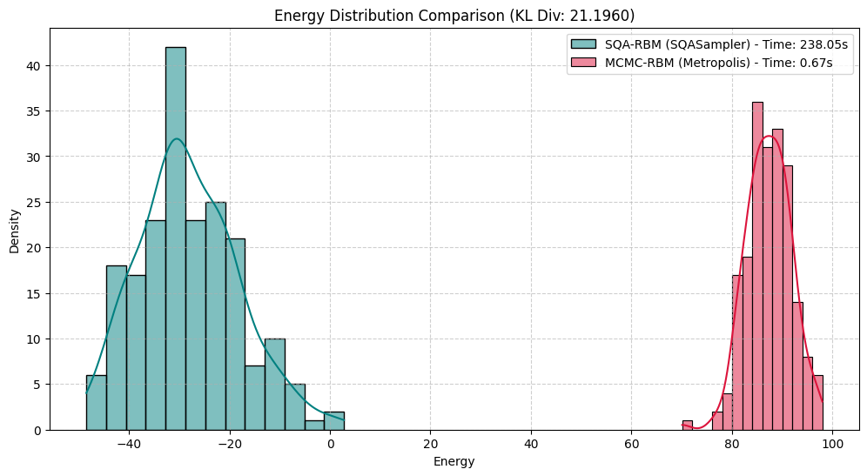
図8 学習後のパラメータでサンプリングした時の分布
ここで、SQA分布の逆温度$\beta$を調節してMCMC-RBMの分布と重なる箇所を探しました。結果は図9のように$\beta = 2.3$のKLダイバージェンスの値が最も小さくなりました。
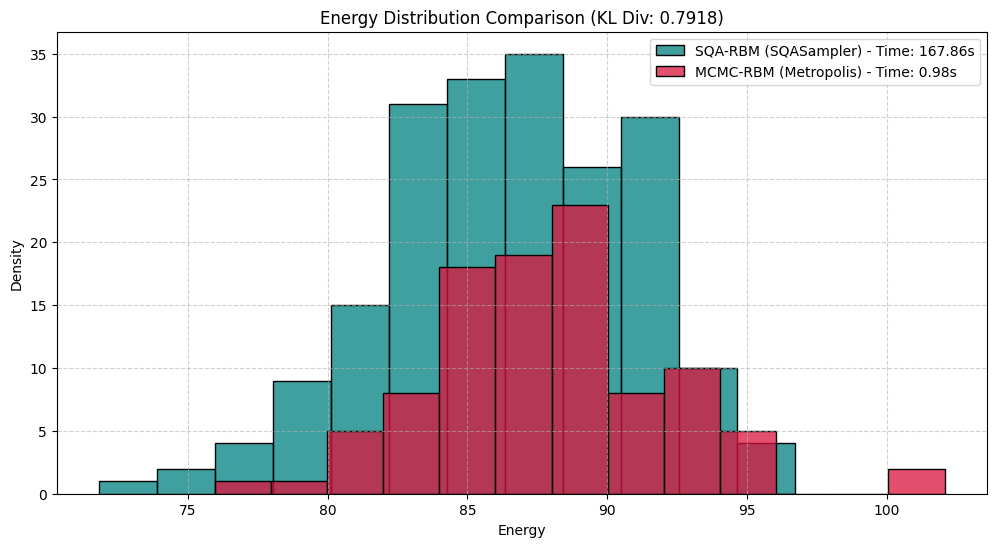
図9 ボルツマン分布に重なるSQAの分布
そこで、改めてSQAのサンプリングの逆温度を$\beta = 2.3$に設定し、その他のパラメータは表2と同じにしてRBMを学習させました。その時のエポック毎の損失誤差の変化は図10のようになり、学習後のテストデータによる画像再構成は図11のようになりました。MSEの値は0.072で図7のMCMC-RBMの結果と一致していることがわかります。
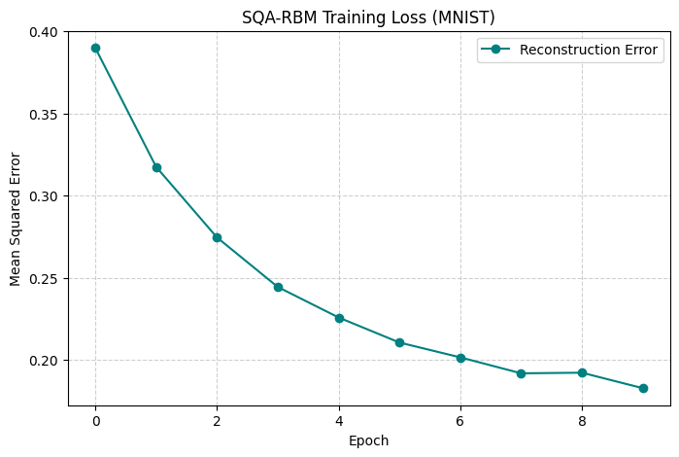
図10 $\beta = 2.3$のSQA-RBMの損失誤差

図11 $\beta = 2.3$のSQA-RBMの画像再構成
考察
実験1のオーバーラップに違いが見られたことについて、まずSQAはサンプリングする毎に初期状態から独立して探索するので、前半5,000個と後半5,000個に相関がない、無関係な値になったと思われます。 一方で、MCMCは一つの初期状態から少しずつ値を更新しながら探索します。そのため、一度エネルギーの谷を見つけるとなかなか更新されません。また式(9)より、そのエネルギーのスピン状態には反転させた状態を合わせて2通りのパターンがあるので双対の山がみられたと考えました。
$$ \begin{align} H(\vec{\sigma}) &= \sum_{i<j} J_{ij} \cdot (-\sigma_i) \cdot (-\sigma_j)\\ &= \sum_{i<j} J_{ij} \cdot \sigma_i \cdot \sigma_j \tag{9} \end{align} $$
実験2について、T=1.0のボルツマン分布に補正しようとした時、SQAの逆温度を考慮すると $\frac{𝛽_{𝑠𝑞𝑎}}{𝛽_{𝑚𝑐}} =2.0$のボルツマン分布となるはずですが、実験の結果では、逆温度は1.6で補正が一致していません。また、式(4)よりトロッター数分の補正をしても、$\frac{𝛽_{𝑠𝑞𝑎}}{𝑚⋅𝛽_{𝑚𝑐}} = 0.25$となり結果と一致しないです。
実験3について、SQAの学習器は過学習(オーバーフィッティング)が起きています。図8の分布よりSQAはエネルギーが低い地点を探索できていることから、最適解を見つけ出し学習データをそっくりと模倣してしまったと考えられます。一方で、MCMCは少しずつ探索していくので、基底状態から少しずれた分布も含み、学習に汎用性を持たすことができたと考えました。そのため、図9のように逆温度を小さくしてサンプリングに幅を持たせたことでSQAの学習を改善することができたと考えられます。
まとめ
SQAのサンプリングの分布はある温度のボルツマン分布に従うことが確認できましたが、SQAの分布をT=1.0のボルツマン分布に補正する時、単純に$J$を逆温度で割るだけでは補正できない原因がわかりませんでした。また、MCMC-RBMとSQA-RBMのサンプリング分布をみると、SQAの分布の方が低エネルギー帯に分布していることがわかり、SQAの逆温度を小さくすると学習を改善することができるとわかりました。
あとがき
今回はD-Waveの実機を使う代わりに、OpenJijのSQAサンプラーで実験しました。SQAの仕組みについて理解を深めつつ、ボルツマン分布に類似するサンプリングとして機能するか考えるきっかけとなりました。ただ、サンプリングには時間がかかる傾向があるため、数$\mu$秒でサンプリングが得られるQAに優位性があると思いました。今後はQAによるサンプリング分布と比較していきたいです。
本記事の作成者
嶋崎司晃(メンタリング:鹿内怜央)