文献情報
- タイトル:Degenerate Quantum LDPC Codes With Good Finite Length Performance
- 著者:Pavel Panteleev and Gleb Kalachev
- 書誌情報(DOI):https://doi.org/10.22331/q-2021-11-22-585
- 出版年:2021年11月
概要
前回に引き続き、qLDPC符号のデコーダであるBP+OSDデコーダについて解説します。前回の記事では、量子誤り訂正符号の基礎を簡単に紹介しました。中でも、スタビライザ符号とそれを表現するパリティチェック行列は今回の記事でも何度も登場する概念なので、わからなくなったら前回の記事を参照してください。
今回の記事では、BP+OSDデコーダの心臓部である確率伝播法 (Belief Propagation, 以下「BP」)を使った復号アルゴリズムについて解説します。「BP+OSD」の「BP」の部分です。
デコーダについて説明する前に、量子誤り訂正符号がエラーをどのように検出するのかを復習しながら、その仕組みをグラフを使って表現する方法について説明します。
復習:量子誤り訂正符号の仕組み
前回の記事で、量子誤り訂正符号の基礎について紹介しました。その中から重要な部分を抜粋して、量子誤り訂正符号がエラーを検出する仕組みについて復習します。
スタビライザ符号は、最も基本的な量子誤り訂正符号です。符号化された状態に対し、スタビライザと呼ばれる物理量の測定でシンドローム値と呼ばれる値を取得することでし、それによってエラーを検出します。エラーとシンドローム値の関係を端的に表現したものがパリティチェック行列でした。
パリティチェック行列は、次のようなバイナリ行列でした。
$$\begin{align}H:=\left(\begin{array}{c|c} 01100 & 10010\\ 00110&01001\\ 00011&10100\\10001&01010 \end{array}\right)\end{align}$$
パリティチェック行列の各行がスタビライザに対応していて、各列はエラーに対応しています。縦線の左側がZエラーを検出し、右側がXエラーを検出します。
パリティチェック行列に対して、パウリエラー(パウリ演算子によって表現されるエラー)$E$をバイナリシンプレクティック表現で表したベクトル $v_E$ をかけると、
$$ \begin{align}Hv_E=\begin{pmatrix}v_{M_1} \odot v_E \\ \vdots \\ v_{M_r} \odot v_E\end{pmatrix} =\begin{pmatrix} s_1 \\ \vdots \\ s_r \end{pmatrix}\end{align} $$
のようにしてシンドローム値 $s_i$が得られるのでした。これが、エラーからシンドローム値が決まる仕組みです。
パリティチェック行列を用いた表現で、エラーとシンドローム値の関係は明確になっていますが、よりわかり易い表現があります。それが、ファクターグラフと呼ばれるグラフを使った表現です。ファクターグラフはパリティチェック行列と一対一に対応していて、誤り訂正符号の構造を表現しています。
ファクターグラフ:誤り訂正符号の構造を表すグラフ
ファクターグラフは誤り訂正符号が持っている構造を埋め込んだグラフです。より正確には、パリティチェック行列をグラフで表現したものです。グラフ理論の言葉を使うと、パリティチェック行列を隣接行列とするグラフのことです。ここでは、グラフに馴染みのない方向けに、パリティチェック行列からグラフが構成される様子を観察します。二部グラフや隣接行列に馴染みがある方は、グラフに関する記法だけ確認して先に進んでも大丈夫です。
簡単な具体例を通して、ファクターグラフを構成していきます。ここでは話を簡単にするために、スタビライザ生成元は $I,Z$のテンソル積で構成されているものとします。このとき、パリティチェック行列は
$$ \begin{align}H=\left(\begin{array}{c|c}O&H_Z\end{array}\right)\end{align} $$
という形をしています。このときは、$H$の成分の左半分はなにもないので、代わりに $H_Z$を考えれば十分です1。
具体例として、行列 $H_Z$を次のように定めます。
$$ \begin{align}H_Z=\begin{pmatrix}1&1&0\\0&1&1\end{pmatrix}\end{align} $$
これは繰り返し符号と呼ばれる符号のパリティチェック行列で、最も簡単な符号のひとつです。このとき、スタビライザの生成元は
$$ \begin{align}(0\;0\;0\;|\;1\;1\;0) \to ZZI \quad (=M_1) \\(0\;0\;0\;|\;0\;1\;1) \to IZZ \quad (=M_2) \end{align} $$
となります。
繰り返し符号がどのようにエラーを検出するのか、順を追って見ていきます。パリティチェック行列についての議論から、エラー $E$についてのBS表現 $v_E$とシンドローム値 $s$について、
$$ \begin{align}Hv_E=\begin{pmatrix}v_{M_1} \odot v_E \\ v_{M_2} \odot v_E \end{pmatrix} = \begin{pmatrix}s_1\\s_2\end{pmatrix}=s\end{align} $$
が成り立ちます。ここで、 $v_E = (x_1\;x_2\;x_3\;|\;z_1\;z_2\;z_3) \in \mathbb Z_2^3\times \mathbb Z_2^3$とおくと、シンドローム値$s$は
$$ \begin{align}s_1=v_{M_1}\odot v_E= x_1\oplus x_2 \\ s_2 = v_{M_2}\odot v_E=x_2\oplus x_3\end{align} $$
となります。ここで、 $\oplus$はmod 2での和(排他的論理和、XOR)です。つまり、シンドローム値 $s_1, s_2$は $x_1,x_2,x_3$から求まるということがわかります。エラーがないときはシンドローム値が0になるので、$s_1, s_2$が両方とも0でなければエラーが検出されたということになります。
このような制約式のことをパリティ検査条件と呼びます。パリティ検査条件こそが誤り訂正符号の構造を直接的に表現しています。誤り訂正符号の空間は、パリティ検査条件の解空間として定義されます。
パリティ検査条件をグラフを使って視覚化します。視覚化の方法は、1つの制約式を1つの四角いノードで表して、制約式に現れる変数を丸いノードで表して、その間を辺で結びます。具体例として式(8)を考えると、次のようなグラフになります。
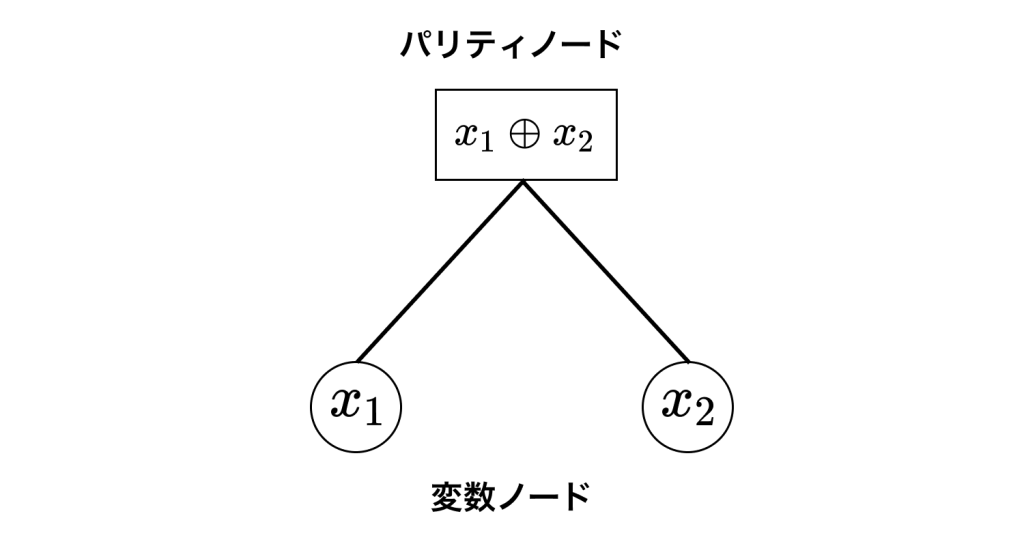
パリティ検査条件に対応する四角いノードをパリティノードと呼び、変数に対応する丸いノードを変数ノードと呼びます。グラフの辺はパリティノードと変数ノードの間にだけ存在して、パリティ検査条件に含まれる変数と接続しています。
量子誤り訂正の文脈では、変数ノードと量子ビットが一対一に対応しています。なぜなら、変数ノードは特定の位置のエラーの有無を表していて、エラーの位置と量子ビットは一対一に対応するからです2。
同じ方法で式2つ目の制約式(9)もグラフにして、パリティ検査条件全体をグラフにすると次のようになります。
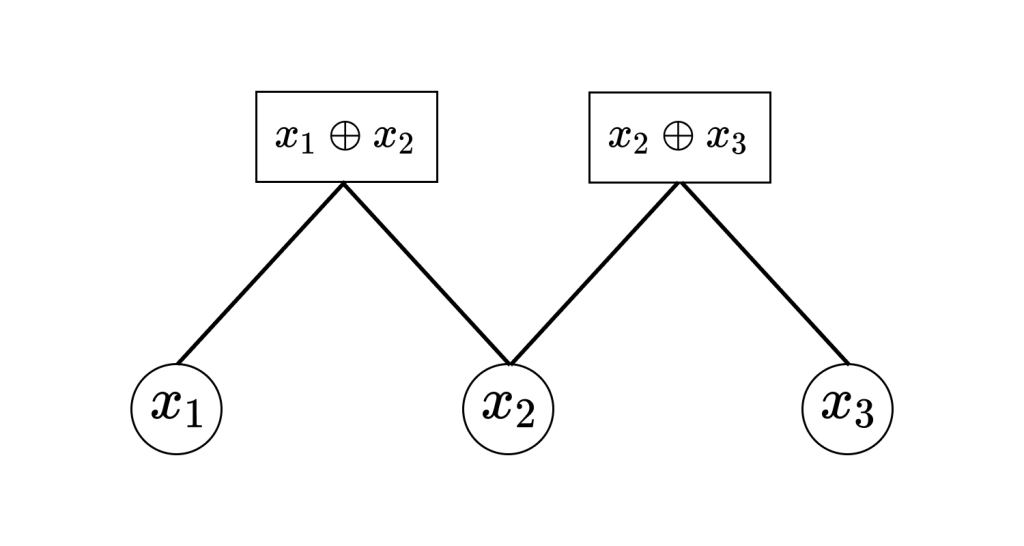
このグラフにはパリティチェック行列 $H$ で指定される符号のすべてのパリティ検査条件が埋め込まれています。このようなグラフを、パリティチェック行列 $H$ に対応する符号のファクターグラフ、あるいはタナーグラフと呼びます。
タナーグラフを使うとエラーとシンドローム値の関係が視覚的にわかることを確認します。 $i$番目の量子ビットにXエラーが起きたとき $x_i=1$となり、そうでないときは0になります。従って、 2番目と3番目の量子ビットにXエラーが起きた場合、ファクターグラフは次のようになります。
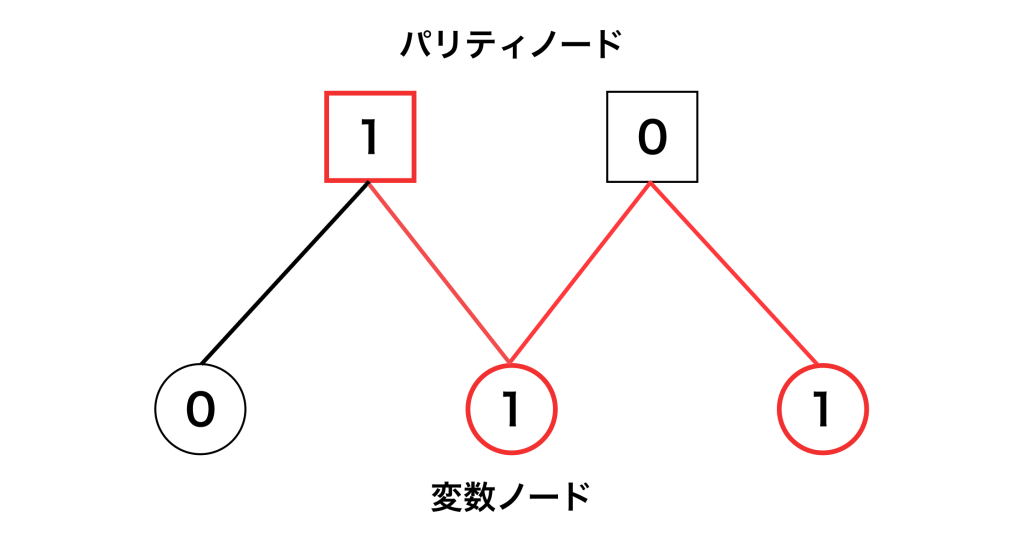
わかりやすさのために、エラーが起きている変数ノードとそこから伸びる辺を赤くしています。このグラフを見ると、変数ノードの値からパリティノードの値を簡単に求めることができます。パリティの値は、辺で繋がった変数ノードの値の排他的論理和を取れば求まります。より単純に、繋がった変数ノードの中で1の数を数えて、偶数個ならパリティは0、奇数個ならパリティは1になります。
このように、ファクターグラフによってエラーからシンドローム値が決定される構造を視覚的に表現することができます。それだけではなく、BP+OSDデコーダの心臓部であるBPでは、ファクターグラフ上でアルゴリズムが実行されます。
これ以降の説明ではファクターグラフの頂点について次のような表記を使います。
- 変数ノードは $v_i$
- パリティノードは $u_j$
- 変数ノード $v_i$ と接続しているパリティノードの集合を $U(v_i)$
- パリティノード $u_j$ と接続している変数ノードの集合を $V(u_j)$
ファクターグラフで見るデコーダの仕組み
この記事の本題はデコーダです。量子誤り訂正符号のデコーダはどんな問題を解くのか、ファクターグラフを使って視覚的に整理します。
先程のファクターグラフの説明で、エラーからシンドローム値が決まることを説明しました。しかし、実際にはエラーがどうなっているかはわからず、シンドローム値だけが得られます。つまり、実際に知ることができるのは次の図のような情報のみです。
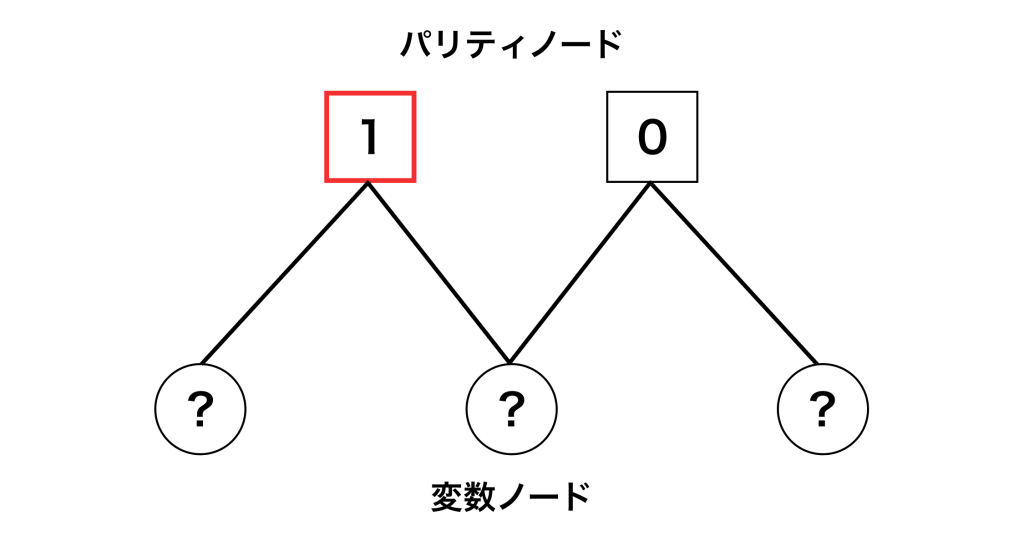
この情報から、エラーがどうなっているかを推定するのがデコーダです。つまり、図の「?」の部分を推定して当てに行きます。
シンドローム値からエラーを推定することは簡単ではありません。エラーからシンドローム値を計算するときは式に当てはめるだけで簡単に計算できましたが、逆向きはそうはいきません。なぜなら、一般に変数の数はパリティの数よりも多く、シンドローム値の情報は変数の値を決定するには不十分だからです。
そこで、確率的な推論をすることになります。変数の値の確率分布と変数とシンドローム値の間の条件付き確率を考えて、シンドローム値が得られたときの変数の値の条件付き確率を求めます。このような推定はベイズ推定と呼ばれ、ベイズの定理と呼ばれる次の式を使って計算します。
$$ \begin{align}p(e|s) = \frac{p(s|e)}{p(s)}p(e)\end{align} $$
ここで、 $s$はシンドローム値を、 $e$はエラーを表します。この式で注目すべきは、左辺が求めたい確率分布で、右辺がエラーの確率分布 $p(e)$や 条件付き確率 $p(s|e)$など比較的わかりやすい確率分布になっているという点です。このときの、 $p(e)$を $e$の事前分布、 $p(e|s)$を $e$の $s$が得られたときの事後分布と呼びます。直感的には、事前分布にシンドローム値 $s$の情報を加えることで、より精度の高いエラー $e$の確率分布 $p(e|s)$が得られるというイメージです。
事後分布が得られれば、前回の記事で紹介したように、事後分布の値を最大にするエラーを推定値として採用することで最も確からしいエラー推定ができることになります。つまり、次の式によってエラーを決定します。
$$ \begin{align}E^* = \arg \max_{E\in P_n} \mathrm{Pr}(E \mid s)\end{align} $$
以上をまとめると、デコーダとはシンドローム値からエラーを推定するプログラムで、それを実現するために事後分布を求めるものです。ただ、式(10)を使って簡単に、そして厳密に事後分布が求めるかと言うと、そんな事はありません。実際には、右辺に出てくる $p(s|e)$や $p(s)$を直接計算することは困難です。
そこで、近似的な手法を使います。確率伝播法と呼ばれる手法は、ファクターグラフのようなグラフを使って表される確率モデルについて、事後分布 $p(e|s)$を効率的に求めることができます。
確率伝播法(BP)
確率伝播法は、グラフで表現される確率モデルについて事後分布 $p(e|s)$を効率的に求めるアルゴリズムです。ここでは、一般的な確率伝播法ではなく、誤り訂正符号のデコードに使われる特殊な確率伝播法について説明します。
確率伝播法は、名前に「伝播」とついているように、情報をグラフ上で伝播させます。どのような情報を伝播させるかというと、観測済みの変数の値の情報と未観測の変数の事前分布の情報です。デコードの文脈では、シンドローム値とエラーの事前分布に対応します。つまり、観測で得られたシンドローム値の値の情報とエラーの事前分布の情報を伝播させます。
このとき、シンドローム値の情報と事前分布の情報は交互に伝播させます。イメージとしては次の図のような感じです。
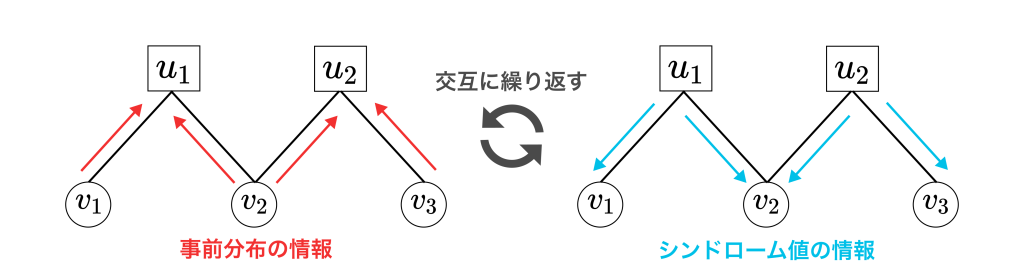
変数ノードからパリティノードへ事前分布の情報を伝播させ、パリティノードから変数ノードへシンドローム値の情報を伝播させます。これを交互に繰り返すことで、メッセージから計算される変数ノードの推定分布が真の事後分布に近づいていきます。
伝播させる情報をどのように計算するのか、最終的に事後分布をどのように計算するのかなどの具体的な話を次節で見ていきます。
LLR-MSA:BPデコーダの効率的な実装
BPを用いたデコーダの効率的な実装として、対数尤度比Min-Sumアルゴリズム(Log-likelihood ratio Min-sum algorithm,以下「 LLR-MSA」)と呼ばれるアルゴリズムが知られています。
LLR-MSAは、ファクターグラフの頂点間のメッセージのやり取りを繰り返すことによって事後分布を計算します。メッセージとは、辺に沿って頂点間を伝播する変数です。
変数ノード $v_j$からパリティノード $u_i$へのメッセージを $m_{v_j\to u_i}$と書くことにします。このとき、メッセージは次の図のようにファクターグラフ上を伝播していきます。
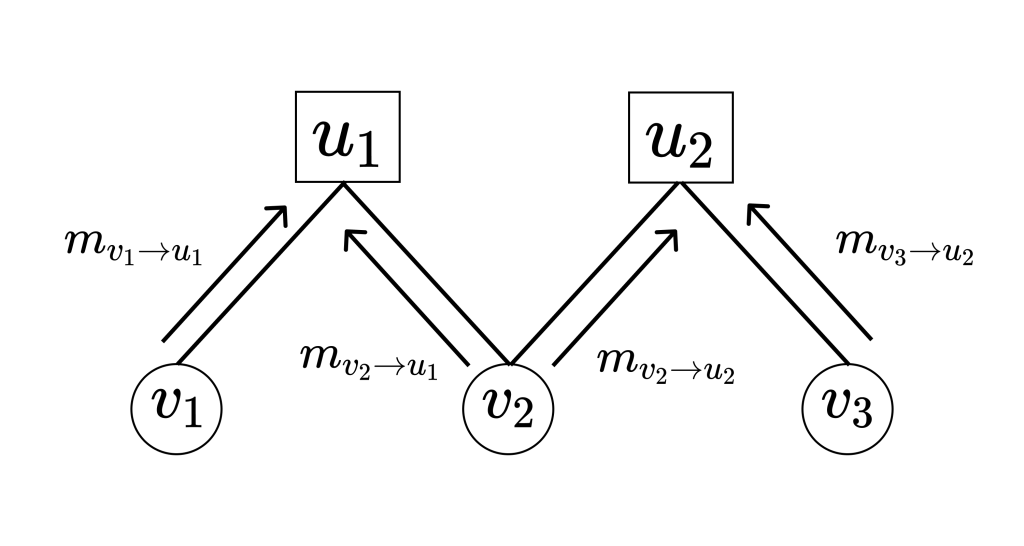
メッセージには、変数ノードからパリティノードへ伝播する $m_{v_j\to u_i}$とパリティノードから変数ノードへ伝播する $m_{u_i\to v_j}$の2種類があります。LLR-MSAの各反復ではこれら2種類のメッセージを伝播させます。これら2種類のメッセージがどのように計算されるかを見ていきます。
変数ノードからパリティノードへのメッセージ $m_{v_j\to u_i}$はLLR-MSAを起動すると最初に送信されるメッセージです。このときのメッセージは次のように計算されます。
$$ \begin{align}m_{v_j \to u_i} = \log\left(\frac{1-p_j}{p_j}\right)=\log\left(\frac{P(e_j=0)}{P(e_j=1)}\right)\end{align} $$
ここで、 $p_j$は$j$番目の量子ビットに $X$エラーが起こる確率を表しています。この式は$j$番目の量子ビットのエラーの事前分布に対応しています。$m_{v_j\to u_i}>0$なら$e_j=0$である確率が高く、$m_{v_j\to u_i} < 0$なら$e_j=1$である確率が高いことを意味します。このように確率の比をとって対数をとった値のことを対数尤度比と呼びます。式(12)で計算される値は、変数ノードの事前分布 $p_j$を用いているので、事前分布の対数尤度比ということになります。LLR-MSAの目標は、メッセージ伝播によって、事後分布の対数尤度比を計算することです。
続いて、パリティノードから変数ノードへのメッセージ $m_{u_i\to v_j}$が更新されます。このときに、変数ノードから受け取ったメッセージ $m_{v_j\to u_i}$を用いていることに注目してください。
やや複雑な式なのでこの式の解釈についてはAppendix Aを参照してください。ざっくりとした意味は、変数ノード $v_j$に向かって、パリティ検査条件をみたすためにどういう値であってほしいのかを表しています。 $m_{u_i\to v_j}$が正なら $v_j=0$であってほしく、負なら $v_j=1$であってほしいということを意味しています。
さらに、パリティノードからメッセージを受け取った変数ノードは次のようにメッセージを計算します。
$$\begin{align}m_{v_j\to u_i}=\log\left(\frac{1-p_j}{p_j}\right)+\sum_{u_i’ \in U(v_j)\setminus u_i}m_{u_i’\to v_j}\end{align}$$
ここまでが1回の反復で計算されるメッセージです。各反復の最後に、暫定的な事後対数尤度比を計算します。
$$ m_{v_j} = \log\left(\frac{1-p_j}{p_j}\right) + \sum_{u_i \in U(v_j)} m_{u_i\to v_j} $$
ここで、事後対数尤度比は次のように定義されます。
$$ \mathrm{LLR}_i = \frac{p(v_i=0 | s)}{p(v_i=1 | s)} $$
したがって、正であれば $v_i=0$である可能性が高く、負であれば $v_i=1$である可能性が高くなります。このことから、暫定的なエラーの推定値を次のように決定します。
$$ \hat{v_i} = \begin{cases}0 & \mathrm{if} \; m_{v_j} > 0 \\ 1 & \mathrm{otherwise}\end{cases} $$
このようにして決定したエラーがパリティ検査条件を満たしていればアルゴリズムを終了して、エラーの推定値を出力します。パリティ検査条件を満たしていなければ、次の反復に進んで再びメッセージの伝播を行います。
このようにして、パリティ検査条件を満たすかあらかじめ決めた最大反復回数に到達するまでメッセージの伝播を繰り返していきます。正しいエラーを出力する保証はありませんが、多くの場合で正しいエラーを出力できることが数値的に検証できます3。
以上の処理をまとめた疑似コードを次に示します。
(https://arxiv.org/abs/2005.07016から引用)
BPだけではダメなのか?
LLR-MSAを用いることでエラーの推定値が得られるので、LLR-MSAだけでデコーダを構成できます。ですが、この記事で紹介しているデコーダにはLLR-MSA以外にOSDと呼ばれるアルゴリズムが付いています。なぜLLR-MSAだけでは不十分なのでしょうか?
LLR-MSAを用いることで事前分布 $\mathrm{Pr}(e)$ から事後分布 $\mathrm{Pr}(e|s)$の推定値が得られます。こうして得られた事後分布を用いて、事後分布を最大にするようなエラーベクトル $\hat e$ をエラーの推定値とすることができます。
$$\hat e = \arg\max_{e\in\mathbb Z_2^n} \mathrm{Pr}(e|s)$$
このような推定はベイズ統計などで用いられる手法で、MAP推定と呼ばれます。MAP推定で得られたエラーベクトルを$\hat e$として、
$$H\cdot\hat e=s$$
が成り立つなら、推定したエラーはシンドローム値に対応した適切な結果である事がわかります。
ただ、MAP推定の結果得られるエラーベクトルは$H\cdot \hat e=s$が成り立たないことがあり、このときは推定に失敗したことになります。失敗した場合は、メッセージ$m_{v_j\to u_i}$を
と更新して、ここまでの手順を繰り返します。これは、ベイズ統計では逐次推定と呼ばれる手法で、得られた事後分布を事前分布とすることでMAP推定を繰り返します。これによって、最初の事前分布 $\mathrm{Pr}(e)$ の影響が弱まり、分布の更新に使われるシンドローム値の情報の影響が強まります。
エラーの推定に成功したら$\hat e$を出力して終了し、失敗を続けて一定の繰り返し回数に達したら推定に失敗したことを報告してアルゴリズムを終了します。事前に繰り返し回数の上限を決めないとアルゴリズムが停止しない可能性があるので注意が必要です。
このようにして、シンドローム値$s$から推定エラー$\hat e$を求めることができます。しかし、量子誤り訂正符号の次のような性質から、十分な精度を得られないという問題があります。
- 確率伝播法を用いて$\mathrm{Pr}(e_j=1|s)$を求めるとき、ファクターグラフにサイクルがあると精度が下がることが知られている。量子誤り訂正符号のファクターグラフにはサイクルが存在するため、量子誤り訂正符号に対しては精度が低い
- 量子誤り訂正符号には、縮退という性質があり、シンドローム値に対応するエラーが複数存在することがある。縮退はBPのメッセージ伝播に対称性を生じさせ、対称性の影響で推定できるエラーに不自然な制約が付いてしまう。
つまり、ここまで紹介した確率伝播法によるデコーダをそのまま使っただけでは十分の性能が得られないということです。そこで、誤り訂正の精度を向上させるために様々な手法が研究されています。次回の記事では、その中でも「順序統計量デコーディング (ordered statistics decoding, OSD)」と呼ばれる手法を用いたデコーダを紹介します。
まとめ
最後まで読んでいただきありがとうございます。今回の記事では、BPを使ったデコーダであるLLR-MSAについて解説しました。LLR-MSAの前提となるファクターグラフを導入して、LLR-MSAの手続きを紹介しました。最後に、LLR-MSAだけではデコーダの精度が不十分であることを説明しました。
次回の記事では、LLR-MSAの精度を補う順序統計量デコーディング (ordered statistics decoding, OSD)と呼ばれる手法を紹介します。OSDは、LLR-MSAの直後に実行することでデコーダの精度を向上させることができます。ぜひ次回の記事もご覧ください。
Appendix A: Min-Sumの更新式の解釈
この付録では次の更新式の意味を詳しく見ていきます
ここで、$V(u_i)$はパリティノード$u_i$に隣接する変数ノード全体の集合、$\mathrm{sign}(-)$は引数の符号を取る関数で、$s_i$はシンドローム値の$i$ビット目です。この式を次の4つのパーツに分けて、赤文字で書かれた番号の順に説明していきます。
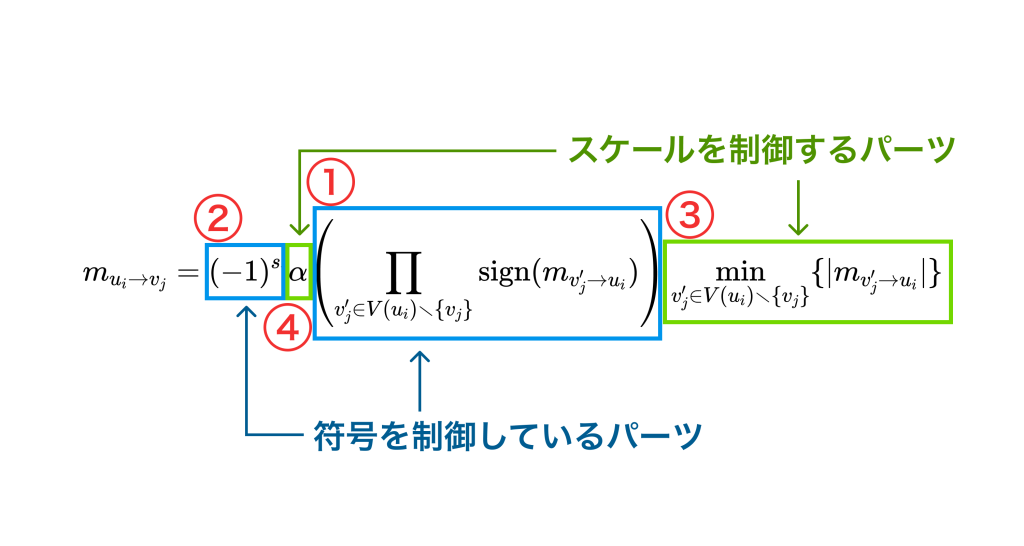
① $\prod \mathrm{sign}(m_{v’\to u})$
まずは、$\prod \mathrm{sign}(m_{v’\to u})$の部分についてです。この部分は、パリティノード$u_i$に送られた$v_j$を除くメッセージの符号を取り、それらをかけ合わせています。$m_{v_j\to u_i}$の符号は
- $+1$なら$j$番目の量子ビットにエラーが起きていない確率のほうが高い($e_j=0$である確率が高い)
- $-1$なら$j$番目の量子ビットにエラーが起きている確率のほうが高い($e_j=1$である確率が高い)
ということを意味しています。このことから$e_j$の値を暫定的に
$$ \begin{align} e_j=\begin{cases}0&\mathrm{sign}(m_{v_j\to u_i})=+1 \\ 1&\mathrm{sign}(m_{v_j\to u_i})=-1\end{cases}\end{align} $$
と決めてしまいます。このようにしたとき、$v_j$を除く変数ノードについてパリティを取った結果が
に対応します。
② $(-1)^{s_i}$
符号を制御しているパーツがもう一つあります。$(-1)^{s_i}$の部分です。この部分には、シンドローム値$s_i$が含まれています。シンドロームの結果に応じて、
- $s_i = 0$なら符号をそのままに
- $s_i=1$なら符号を反転する
という挙動をします。これによって、$\prod \mathrm{sign}(m_{v’\to u})$で計算された$v_j$以外のパリティに対して、それを反転するかどうかを決定できます。そもそも、シンドローム値の意味は
- $s_i=0$なら、パリティノード$u_i$に隣接する変数ノードに生じたエラーの数が偶数個
- $s_i=1$なら奇数個
です。つまり、
$$ \begin{align}(-1)^{s_i}=\prod_{v_j \in V(u_i)}\mathrm{sign}(m_{v_j\to u_i})\end{align} $$
となるべきです。従って、
が成り立ちます。
符号については以上2つのパーツから決定できました。残る2つのパーツは$m_{u_i\to v_j}$の大きさを制御する部分にあたります。
③ $\alpha$
まずは、スケーリングのための因子としてある$\alpha$について簡単に説明します。この部分は、Min-Sumアルゴリズムに直接関係しているものではなく、性能向上のために調整される因子です。ここでは、反復回数 $i$に応じて
$$ \begin{align}\alpha = 1-2^{-i}\end{align} $$
と定めています。
④ $\min|m_{v\to u}|$
続いては、$\min|m_{v\to u}|$の部分についてです。この部分は直接意味を解釈することは困難です。Min-Sumアルゴリズムには元ネタとなるSum-Productアルゴリズムと呼ばれるアルゴリズムがあり、その近似がMin-Sumアルゴリズムになっています。では、元ネタのSum-Productアルゴリズムではメッセージがどうなっているかと言うと、
となっています。Min-Sumと最大の違いは、$\min$の部分が$\tanh$を含む別の関数に置き換わっていることです。なぜtanh関数が使われているかというと、対数尤度比関数$L(x)=\log(P(x=0)/P(x=1))$について
$$ \begin{align}\tanh(L(x)/2) = (e^{L(x)} – 1) / (e^{L(x)} + 1) = \frac{P(x=0) – P(x=1)}{P(x=0) + P(x=1)}=P(x=0)-P(x=1)\end{align} $$
が成り立ち、$x=0$である確率と$x=1$である確率の差に対応しているからです。この差が大きければ大きいほど、その確率の信頼性は高まり、逆に差が小さいと信頼性が低くなります。極端な例として、$P(x=0)=P(x=1)=0.5$であれば$\tanh(L(x)/2)=0$となります。これは、$x=0$なのか$x=1$なのか全くわからないという状況を意味しています。
このように$\tanh$を用いて定義されるSum-Productアルゴリズムは理論的には優れていますが、実用的には$\tanh$の計算に時間がかかり効率的ではありません。そこで、$\tanh$の部分を$\min$を使った関数に置き換えたものがMin-Sumアルゴリズムです。$\min$を使った関数で近似できることを確認するために、2変数の単純な場合を考えます。Sum-Productのメッセージ計算に使われる関数の2変数版は
$$ \begin{align}z = 2\tanh^{-1}\left(\tanh\left(\frac {|x|}2\right)\tanh\left(\frac {|y|}2\right)\right)\end{align} $$
であり、それを次の式で近似します。
$$ \begin{align}z = \min\{|x|,|y|\}\end{align} $$
かなり単純な式になりますが、これら2つの関数は外形がよく似ています。そのことを見るために2つの関数を比較したグラフを次に示します。ただし、 $x = y$となる2次元平面で切断したグラフであることに注意してください
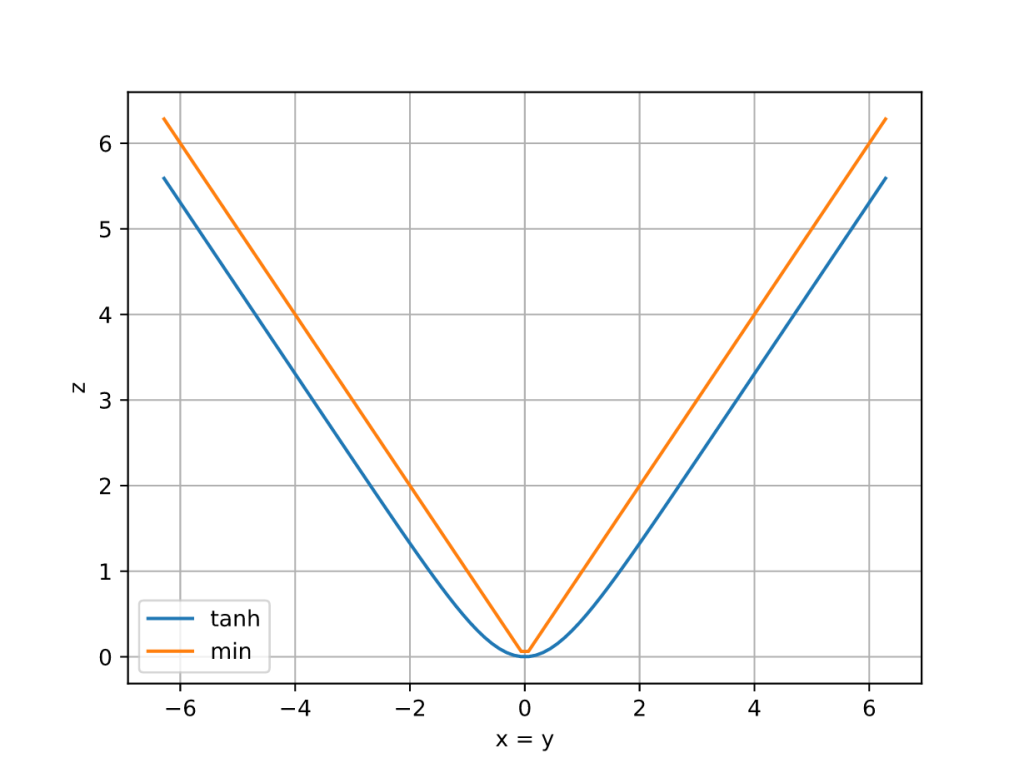
青い線が $\tanh$を用いた真の値で、オレンジの線が $\min$を用いた近似を表しています。値は異なりますが、グラフの概形がよく似ている事がわかります。
このことから、メッセージ計算のための関数
を計算が簡単な関数
で近似したものがMin-Sumアルゴリズムになります。
- このような符号は $X$ エラーだけを検出できるので古典誤り訂正符号と同一視できます ↩︎
- 一般には、変数ノードはエラーの発生箇所と対応しています。したがって、量子ビット以外にもエラーが起こる場合でも表現できます。この場合は、パリティチェック行列だけでなく、操作全体のエラーとシンドローム値の関係を記述する必要があります。このようなモデルとしてdetector error modelと呼ばれるものが知られていて、より現実的なノイズモデルを記述できます。 ↩︎
- 一般のファクターグラフについて、この繰り返しで正確な事後分布に収束するとは限らないことに注意が必要です。むしろ、正確な事後分布に収束することが保証されているのはファクターグラフが木構造(閉路がないグラフ)のときのみです。つまり、閉路が含まれるファクターグラフについては不正確なアルゴリズムになります。しかし、閉路が含まれるファクターグラフについてもある程度の精度で事後分布を求められることが知られていて、loopy belief propagationと呼ばれています。loopy belief propagationについては収束性について解析することが難しく、収束の正確な条件はわかっていないようです。 ↩︎