文献情報
- タイトル:Degenerate Quantum LDPC Codes With Good Finite Length Performance
- 著者:Pavel Panteleev and Gleb Kalachev
- 書誌情報(DOI):https://doi.org/10.22331/q-2021-11-22-585
- 出版年:2021年11月
概要
前回の記事では、LLR-MSAと呼ばれるBPを使ったデコーダについて紹介しました。LLR-MSAはシンドローム値からエラーの起きた確率を効率よく求めることができます。一方で、量子誤り訂正符号の縮退と呼ばれる性質やファクターグラフの閉路の影響でエラー確率が正しく推定できないという問題がありました。
今回の記事では、LLR-MSAの精度を補う順序統計量デコーディング(Ordered Statistics Decoding, 以下「OSD」)と呼ばれるアルゴリズムを紹介します。OSDをBPの直後に実行することで、デコーダの精度を向上させる事ができます。はじめに古典誤り訂正符号のOSDについて、そのモチベーションと具体的な仕組みついて解説します。続いて、古典OSDを量子誤り訂正符号に対応する形に拡張します。最後に、BPとOSDを統合してこの記事の主役であるBP+OSDデコーダの全体像を解説します。
OSDのモチベーション
ここまでで紹介した確率伝播法を用いたアルゴリズムを用いて、シンドローム値$s$から $\mathrm{Pr}(e_j=1|s)$を求めることができます。この事後確率を $p_j$として、
$$ \begin{align}\hat e_j=\begin{cases}0&p_j \le 0.5 \\ 1&p_j>0.5\end{cases}\end{align} $$
のようにして推定エラー$\hat e$を得ることができます。MAP推定としてはある程度の精度があると期待できますが、実際に
$$ \begin{align}H\hat e=s\end{align} $$
を満たさないとエラーとしての条件を満たしません。
仮に推定エラー$\hat e$がこの条件を満たさなかったとしたらどうしたらいいでしょうか?デコーダの訂正性能を高めるためには、この推定エラー$\hat e$に僅かな修正を加えてシンドローム条件を満たすようにすることが考えられます。推定エラーは条件を満たしていなくても、真のエラーに近いことが期待できます。そこで、修正の基本戦略を「$\hat e$の成分の中で信頼性の高い成分を残して、それ以外を条件を満たすように置き換える」とします。これが順序統計量デコーディング(ordered statistics decoding, OSD)の基本的なアイデアになります。このアルゴリズムは探索空間の特殊な構造のおかげで貪欲法を適用することができ、ある程度効率が良く精度もいいアルゴリズムになっています。
以下では古典誤り訂正符号についての順序統計量デコーディングを紹介した後に、それを量子誤り訂正符号に適用する方法を説明します。ここから先は順序統計量デコーディングのことをOSDと略して表記します。
情報集合
まずは、OSDのアルゴリズムの説明に必要となる情報集合と呼ばれる概念を導入します。
添字集合$I\subseteq [n]$が、パラメータが$[n,k,d]$である古典誤り訂正符号$\mathcal C$に対して、
$$ \begin{align}\mathcal C_I=\{c_I\mid c\in \mathcal C\} = \mathbb Z^k_2\end{align} $$
をみたすとき、$I$は情報集合であるといいます。ここで、$c_I$はビット列$c$を添字集合$I$で限定したものを表します。つまり、$I=\{i_1,…,i_k\}$なら、
$$ \begin{align}c_I=(c_{i_1},…,c_{i_k})\end{align} $$
ということになります。同様にして行列$H$についても、$H=(h_1,…,h_n)$について
$$ \begin{align}H_I=(h_{i_1},…,h_{i_k})\end{align} $$
とします。
情報集合にはパリティチェック行列を用いた同値な言い換えが知られています。誤り訂正符号 $\mathcal C$についての添字集合 $I$とパリティチェック行列 $H$について、
$$ \begin{align}Iが情報集合である \Leftrightarrow \mathrm{rank}(H_{I^c})=\mathrm{rank}(H)\end{align} $$
が成り立ちます。ここで、 $I^c$は $I$の補集合を表します。つまり、 $H$のランクが変わらないように $I^c$を選べば $I$が情報集合になります。このことから、パリティチェック行列 $H$の線形独立な列を選択することで $\mathcal C$の情報集合の補集合が得られます。このように、線形独立な列の選択で情報集合を構成できるという事実は、アルゴリズムの内部で情報集合を構成するときに便利です。
また、便利な記法として次の記法を導入します。
$$ \begin{align}\mathcal E^s_I(u)=v \;:\Leftrightarrow v_I=u,Hv=s\end{align} $$
この記法の意味は、ビット列$u$を含みながらシンドローム条件を満たすようなビット列$v$を表しています。これによって、$\hat e$の$I$で指定される成分以外を無視して、シンドローム条件を満たすように修正したビット列を表しやすくなります。
OSDの手順
OSDでまず最初にやりたいことは、$\hat e$の中から信頼性の高い成分を選ぶことです。信頼性の高い成分を残して、その他の成分を置き換えるという処理を行います。そのためにまずは、$\hat e$の成分の信頼性を考えます。真のエラーを$e$として、第 $i$成分の信頼性を
$$ \begin{align}\rho_i:=\mathrm{Pr}(e_i=\hat {e_i} \mid s)=\max\{p_i,1-p_i\}\end{align} $$
で評価することにします。ここで、 $p_i = \mathrm{Pr}(e_i = 1\mid s)$であり、シンドローム値が得られたうえで $i$番目の量子ビットにエラーが起きている確率です。注意すべきこととして、式の途中で真のエラー $e$ が登場していますがこれは知り得ない情報です。それでも、最右辺では $p_i$ しか使われていないため計算することができます。
$\hat e$の成分でそのまま残すものは $\hat e$の情報を持っていてほしいので、ここでは符号 $\mathcal C$の情報集合になっていると考えます。この考えに基づいて最も信頼性の高い情報集合だけを残すようにします。各成分の信頼性が独立であると仮定したとき、情報集合$I$の信頼性は
$$ \begin{align}\rho(I):=\mathrm{Pr}(\mathcal E^s_I(\hat e_I)=e)=\prod_{i \in I}\rho_i\end{align} $$
と書くことができます。信頼性の高い成分を選ぶという問題は$\rho(I)$を最大にする情報集合$I$を探すという問題に置き換えられました。
$\rho(I)$の最大化は一見すると複雑で計算の効率が悪そうですが、実は情報集合全体の集合$\mathcal B$がマトロイドという構造を持っているため、貪欲法を用いて効率的に計算できることが知られています。
まずは積の最大化になっているところを、対数を取って和の最大化に置き換えて
$$ \begin{align}\max_{I\in \mathcal B}\sum_{i\in I}\ln \rho_i\end{align} $$
という最適化問題に書き換えます。これはマトロイド上の最大独立集合問題と呼ばれる問題で、貪欲法を用いて効率的に解くことができます。(アルゴリズムの詳細はこちらのスライドなどを参照してください)
この問題を
このようにして得られた信頼性の高い情報集合$I$について、$\hat e$の$I$以外の要素を置き換えることでシンドローム条件を満たすようにすることを目指します。$I^c$で$I$の補集合を表すことにして、
$$ \begin{align}H(\hat e_I+x_{I^c})=H\hat e_I+Hx_{I^c}=H_I\hat e_I+H_{I^c}x_{I^c}=s\end{align} $$
をみたすようなビット列$x$を求めて、
$$ \begin{align}\hat e’=\hat e_I+x_{I^c}\end{align} $$
とすることで置き換えを実現します。このような$x$は
$$ \begin{align}H_{I^c}x_{I^c}=s+H_I\hat e_I\end{align} $$
をみたし、この方程式を解くことによって得られます。以上でシンドローム条件をみたす推定エラー$\hat e’$が得られます。
ここまで紹介した手順に従うOSDは**order-0 OSD (OSD-0)**と呼ばれています。具体的なアルゴリズムは次のようになります。注意すべきこととして、入力のパリティチェック行列 $H$は信頼度が $\rho_1 \le \cdots \le \rho_n$ となるように列 $(h_1,…,h_n)$が並び替えられています。そのため実装する際には、事前にソーティングが必要になります。
- Input: binary parity-check matrix $H$, syndrome vector $s \in \mathbb F_2^m$, vector of hard decisions $\hat e \in \mathbb F^n_2$
- Output: error vector $e \in \mathbb F_2^n$ such that $He=s$
- $J \leftarrow \emptyset$
- for $i \leftarrow 1$ to $n$ do
- if $\mathrm{rk}H_J = \mathrm{rk}H$ then
- break;
- $J’ \leftarrow J \cup \{i\}$
- if $\mathrm{rk} H_{J’} > \mathrm{rk}H_J$ then
- $J \leftarrow J’$
- if $\mathrm{rk}H_J = \mathrm{rk}H$ then
- end
- $s’ \leftarrow s_J$
- $x \leftarrow$ solution of $H_Jx = s’$
- return $e = \mathcal R^x_J(\hat e)$
OSDのバリエーション
実は、OSD-0を拡張することで誤り訂正の精度をさらに向上させる事ができます。どのように拡張するかというと、 $\hat e$の成分のうち、置き換える成分の加増を増やします。このような拡張版のOSDをorder-w OSD (OSD-w)と呼びます。
OSD-0では、信頼性の低い成分を $J$で指定して置き換えました。OSD-wでは $J$に加えて、信頼性の低い成分をさらに $w$個指定して置き換えるということを行います。

(引用元:https://arxiv.org/abs/1904.02703)
その他のバージョンとして、OSD-0の改良版アルゴリズムがあります。このアルゴリズムでは、情報集合の補集合を完全に求めるということはせず、 $x$を求めるための方程式 $H_Jx = s’$に解が存在するようになるまで $J$を拡大させます。このようにして得られる添字集合 $J$は、信頼性の高い情報集合 $I$について $I \subseteq J^c$をみたすので、 $\hat e_J$を置き換えても情報集合に影響しません。
改良版のアルゴリズムは次のようになります。

(引用元:https://arxiv.org/abs/1904.02703)
ここで、新しい記法として $\mathcal R^x_J$という関数が登場しています。この関数の意味は、ベクトルを受け取って、その中の $J$で指定される成分をベクトル $x$で置き換えるというものです。
このアルゴリズムの各ステップで行っている処理は次のように解釈できます
- 1行目: $J$の初期化。 $J$はこの後、情報集合の補集合として使われる集合です
- 2行目: $s’$の初期化。 $s’$は最終的に $s+ H_{J^c}\hat e_{J^c}$にすることが目標です
- 3行目から12行目:情報集合の補集合 $J$を求めています
- $J$は $H_J$が線形独立になるように選びます。その理由は、 $\mathrm{rk}H_J=\mathrm{rk}H$ならば $J$は情報集合の補集合になるからです
- 4行目から6行目:拡大係数行列 $(H_J|s’)$のランクが $H_J$のランクと一致したらループを抜けます。
- この条件でループを抜ける理由は$\mathrm{rk}(H_J|s’) = \mathrm{rk}H_J$のとき $H_Jx = s’$が解を持つからです
- 7行目:添字 $i$を添字集合 $J$ に追加したものを新たな集合 $J’$に代入
- 8行目から11行目:$H_{J’}$のランクが $H_J$のランクよりも大きいとき、 $J$を $J’$で置き換えて、 $s’$に $\hat e_i h_i$を足します。ここで、 $\hat e_i$は スカラー、 $h_i$は $H$の $i$番目の列ベクトルです
- なぜ $\mathrm{rk}H_{J’}$と $\mathrm{rk}H_J$を比較しているかというと、 $\mathrm{rk}H_{J’} > \mathrm{rk}H_J$ならば $H_{J’}$の列は線形独立であることが保証できるからです( $J$は空集合で初期化されていて、 $H_J$の列が線形独立で $\mathrm{rk}H_{J’} > \mathrm{rk}H_J$ならば $H_{J’}$の列が線形独立であることが帰納的に証明できます)
- $s’$に $\hat e_i h_i$を足している理由は、 $H\hat e=\sum_{k=1}^n \hat e_k h_k$であることから、 $J$に追加した $i$の項を打ち消したいからです。こうすることで、最終的に得られる $s’$が $s + H_{J^c}\hat e_{J^c}$になります
- 13行目: $H_J x = s’$を解くことで $x$を求めています
- 14行目: $\hat e$のうち、信頼性の低い $\hat e_J$の部分を $x$に置き換えることで、 $e$がシンドローム条件 $He=s$をみたすようにします
量子誤り訂正符号への拡張
ここまで紹介したOSDは古典誤り訂正符号に対するアルゴリズムでした。本題は量子誤り訂正符号に対するアルゴリズムなので、ここまでで紹介したものを量子誤り訂正符号へ拡張します。
拡張と言っても、アイデアは簡単で、量子誤り訂正符号の言葉をBS表現の要領でビット列に変換して、それをOSDの入力とします。さらに、OSDの出力である推定エラーのビット列を量子のエラーに変換することで、全体として量子誤り訂正のためのアルゴリズムとして動作するようにします。まとめると、処理の流れは次の図のようになります。
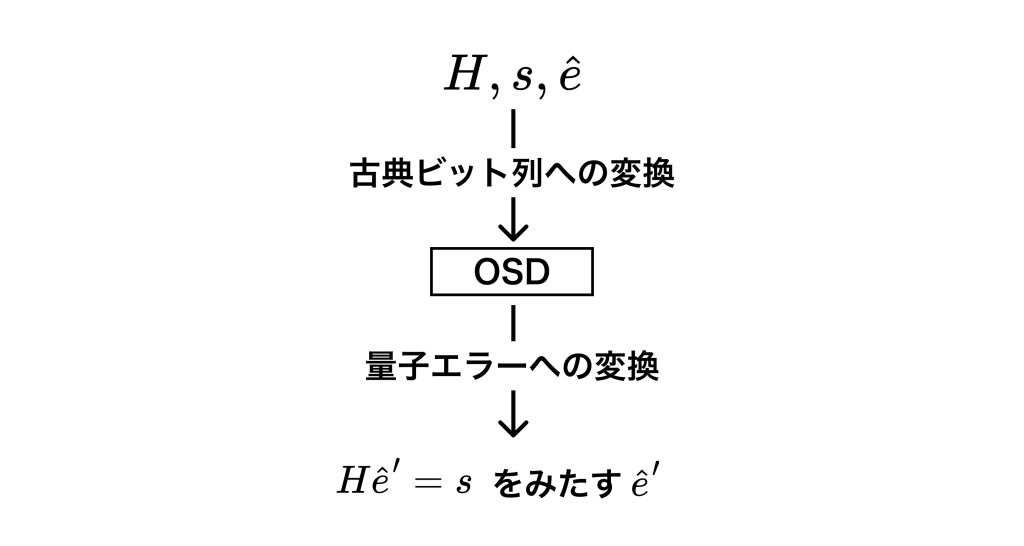
入力として受け取ったパリティチェック行列 $H$と推定エラー $\hat e$について、古典ビット列への変換 $\mathbb b$を定義します。基本的なアイデアはBS表現と同様ですが、成分の並び方がすこし違うので注意してください。
- $n$量子ビットパウリ演算子 $\hat e = \hat e_1 \otimes \cdots \otimes \hat e_n \in P_n$ に対して、 $\hat e_i = i^{l_i}X^{a_i}Z^{b_i}\quad (a_i,b_i \in \mathbb Z_2, \;l\in\mathbb Z_4)$で定まる $\{a_i,b_i\}$を用いて変換 $b$を次のように定めます
$$ \begin{align}b(\hat e) = (a_1,b_1,…,a_n,b_n) \in \mathbb F_2^{2n}\end{align} $$
- パリティチェック行列 $H = (H_{i,j})\in \mathbb F^{m\times 2n}$に対して、各行を次のように並べ替えたものを $b(H)$とします
$$ \begin{align}(H_{i,1}\;H_{i,2}\;\cdots \; H_{i,2n-1}\;H_{i,2n}) \mapsto (H_{i,1}\;H_{i,n+1}\;\cdots \; H_{i,n}\;H_{i,2n})\end{align} $$
このような変換を用いることで、パリティチェック行列 $H$と エラー $\hat e \in P_n$と、そのシンドローム値 $s$の間に
$$ \begin{align}s =b(H)b(\hat e)\end{align} $$
という関係が成り立つことが示せます。
この変換 $b$を用いて、量子版のOSDを構成します。古典版のOSD-wを $\mathrm{OSD}_w(|\cdot|_{\mathsf{Sp}}, H,e)$ と書くことにして、量子版のOSD-wである $\mathrm{qOSD}_w$ を
$$ \begin{align}\mathrm{qOSD}_w=b^{-1}(\mathrm{OSD}_w(|\cdot|_{\mathsf {Sp}},b(H), b(e)))\end{align} $$
で定義します。ここで、 $\mathrm{OSD}_w$に重み関数として渡されている $|\cdot |_{\mathsf{Sp}}$はシンプレクティック重み関数と呼ばれ、
$$ \begin{align}|x|_{\mathsf{Sp}}=\sum^n_{i=1}x_{2i-1}\lor x_{2i} \end{align} $$
で定義されます。重み関数の選択はエラーの特性に応じて行います。ここでは、エラー $X,Z,Y$が当確率で各量子ビットに独立にかかるエラーを仮定してシンプレクティック重み関数が選択されています。より一般には、最も確率が高いエラーが最も小さい重みを持つような重み関数をエラーの特性に応じて選択します。
BPとOSDの統合:BP+OSDデコーダ
ついにこの記事の主役であるBP+OSDデコーダを紹介します。前回の記事で紹介したBPデコーダであるLLR-MSAと、今回の記事で紹介したOSDを統合します。
前回の記事を振り返ると、LLR-MSAはシンドローム値を受け取って、各量子ビットにエラーが起きている確率を出力するアルゴリズムでした。このLLR-MSAを $X$エラーと $Z$エラーのそれぞれについて実行します。すると、 $i$番目の量子ビットに $X$エラーが起きている確率 $p_{i,X}$と $Z$エラーが起きている確率 $p_{i,Z}$が得られます。エラーの起き方は4種類で、それぞれ次のようになります
- $X$エラーも $Z$エラーも起きない
- $I$エラー(エラーが起こらない)
- 確率は $(1-p_{i,X})(1-p_{i,Z})$
- $X$エラーが起きて $Z$エラーは起きない
- $X$エラー
- 確率は$p_{i,X}(1-p_{i,Z})$
- $X$エラーも $Z$エラーも起きる
- 実質的に $Y$エラー
- 確率は $p_{i,X}p_{i,Z}$
- $X$エラーは起きず $Z$エラーは起きる
- $Z$エラー
- 確率は $(1-p_{i,X})p_{i,Z}$
この4種類のエラーの確率を新たに $p_{i,I},p_{i,X},p_{i,Y},p_{i,Z}$とします。この値を用いて、 $i$番目の量子ビットの推定エラー $\hat e_i$を次のように決定します。
$$ \hat{e}_i = \mathop{\arg\max}\limits_{E\in \{I,X,Y,Z\}} p_{i,E} $$
こうして得られた、エラー確率 $p_{i,I},p_{i,X},p_{i,Y},p_{i,Z}$と推定エラー $\hat e_i$を使ってOSDの入力データを作ります。OSDの入力として必要だったのはシンドローム値 $s=(s_1,…,s_m)$、推定エラー $\hat e=(\hat e_1,…,\hat e_n)$、そして列が信頼度順に並んだパリティチェック行列 $H$です。最初の2つはすでに得られているので、作る必要があるのは並び替えられた $H$だけです。
パリティチェック行列 $H$の列を信頼度順に並び替えるためには信頼度を求める必要がありますが、信頼度はエラー確率 $p_{i,I},p_{i,X},p_{i,Y},p_{i,Z}$から求める事ができます。 $i$番目の量子ビットの信頼度 $\rho_i$は、 $p_i=p_{i,X}+p_{i,Y}+p_{i,Z}$を用いて、
$$ \rho_i = \max\{p_i, 1-p_i\} $$
で求める事ができます。こうして得られた信頼度 $\rho_i$を用いて、パリティチェック行列 $H=(h_1,…,h_n)$の列を信頼度順に並び替えます。並び替えは高速なソーティングアルゴリズムで行えば $O(n \log n)$で実行できます。以上で、OSDの入力をすべて揃える事ができました。
ここまでの手順をまとめると次のようになります。

(引用元:https://arxiv.org/abs/1904.02703)
簡単に計算量について考察します。BP部分の計算量は、繰り返し回数の上限を決めることで線形時間で動作します。一方のOSDの部分では、アルゴリズムの内部でランクを計算していて、その際にガウスの消去法を使うため $O(n^3)$かかります。結果的に、BP+OSD全体で計算量が $O(n^3)$になります。計算量が $O(n^3)$であることは、多項式時間であるという点では効率的ですが、実用上は大きすぎると考えられています。デコーダの計算量は量子コンピュータの性能に直結する重要な要素なので、OSDの代わりにより計算量の少ない処理が多く提案されていて、現在も研究が続いています。
まとめ
最後まで読んでいただきありがとうございます。今回の記事では、OSDについてその仕組みを説明して、最後にこの記事の主役であるBP+OSDデコーダを見ました。OSDは情報集合が持つマトロイドという構造をうまく使うことで正しい推定エラーを効率的に得るアルゴリズムでした。OSDを使うことで、条件を満たさない推定エラーを条件をみたすように変換する事ができ、これによってBPのデコード精度を補うことができます。一方で、実用上は計算量が重いので、より効率的なアルゴリズムが研究されています。
3本の記事を通して、量子誤り訂正符号の基礎、 LLR-MSA、OSDについて紹介し、BP+OSDデコーダの仕組みを見てきました。なるべく自己完結するように書いた結果、とても長い記事になってしまいましたが、改めて最後まで読んでいただきありがとうございます。量子誤り訂正符号やそのデコーダについて興味を持つきっかけになれれば幸いです。